Chez DocDoku nous animons des formations sur les outils et frameworks pour le développement front-end. Les trois principaux acteurs du marché sont aujourd’hui React, Vue et Angular. Ils offrent tous les trois la possibilité d’écrire du code de manière déclarative pour créer nos interfaces.Néanmoins, si nous devions réaliser une petite application, choisir un de ces framework pourrait paraître surdimensionné. Alors pourquoi ne pas réaliser un petit framework maison ? Il y a en effet plusieurs technologies à notre disposition pour ce faire. Nous vous proposons d’en étudier quelques-unes dans cet article.
Les deux technologies que nous allons aborder sont les Web Components (suite de technologies HTML5) et les décorateurs TypeScript qui vont nous permettre d’effleurer la surface de la réalisation d’un framework.
Les Web Components
Les Web Components sont un regroupement de trois technologies HTML5 :
- Les custom elements
- Les shadow root
- Les templates
La principale caractéristique des Web Components est la possibilité de créer des éléments personnalisés, par exemple enrichir des éléments existants comme un champ de texte, un bouton, etc. C’est aussi la possibilité de créer de nouveaux éléments HTML (balises) avec un apport sémantique dans la construction de nos applicatifs, par exemple une nouvelle balise HTML my-todo-list qui construirait elle même ses sous-éléments. Nous parlons alors de custom elements.
Voici le code le plus simple pour définir une nouvelle balise :
class MyTodoList extends HTMLElement {
constructor() {
super();
}
}
customElements.define("my-todo-list", MyTodoList);
Une autre caractéristique notable est l’isolement (encapsulation) de l’HTML sous-jacent. Notre nouvelle balise et son contenu enfant peuvent être totalement « détachés » du reste de la page et ainsi ne subir aucun impact du reste du DOM, avoir sa propre feuille de style locale, et ne pas impacter les autres éléments voisins. C’est le rôle du shadow DOM.
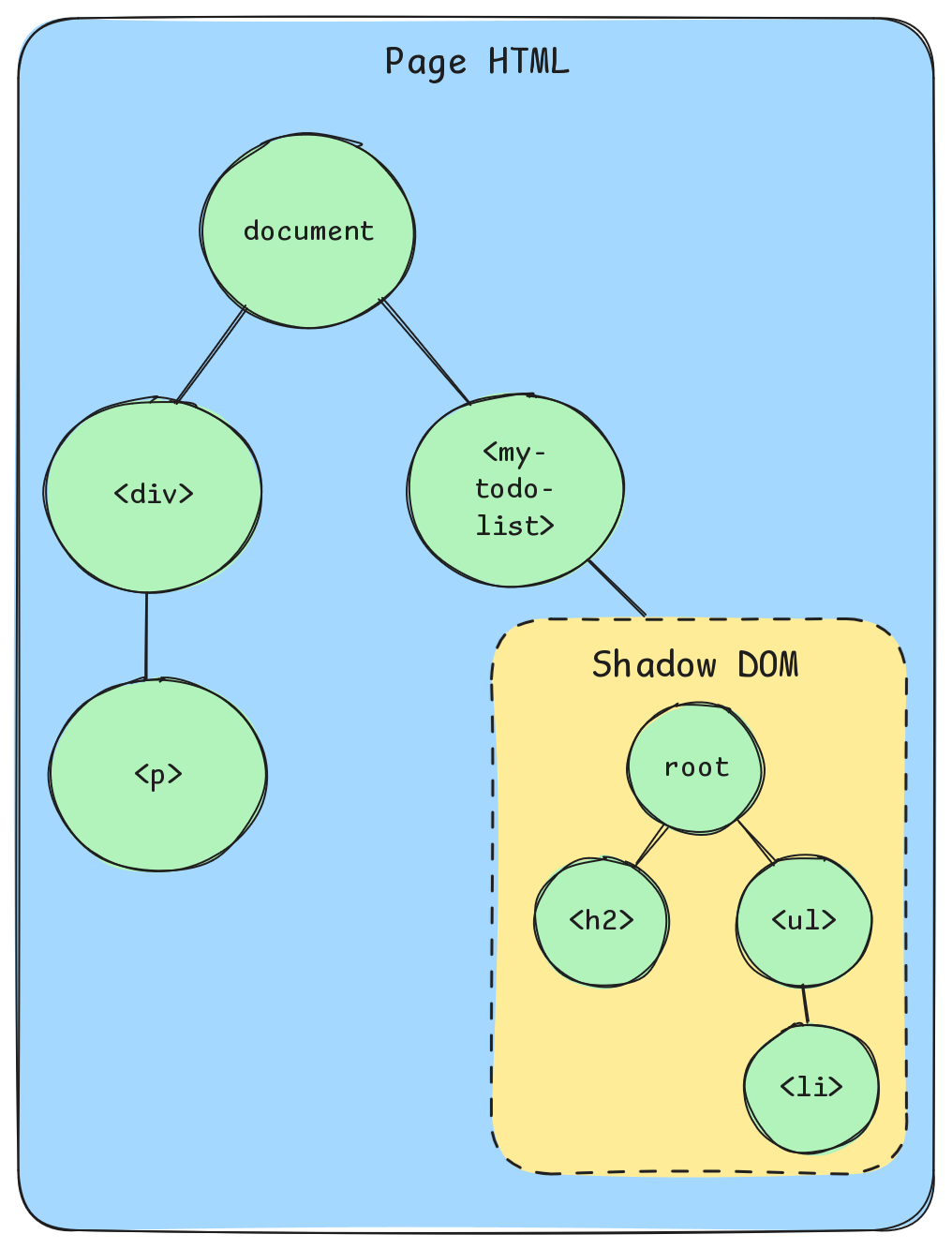
Finalement nous pouvons nous passer de l’écriture fastidieuse en JavaScript de la construction des éléments enfants en utilisant la balise template. Cette balise nous permet d’écrire le contenu de nos éléments personnalisés directement en HTML. Aussi nous pouvons combiner les templates avec l’utilisation de la balise slot afin de rendre nos templates paramétrables.
Utilisation de la balise template :
Hello todo list
- Do this
- Do that
Instanciation d’un élément depuis ce template :
let template = document.getElementById("my-todo-list-template");
let templateContent = template.content;
document.body.appendChild(templateContent);
Exemple complet avec ces trois technologies :
Default title
- Do this
- Do that
Hello todo list 1
class MyTodoList extends HTMLElement {
constructor() {
super();
const template = document.getElementById('my-todo-list-template');
const templateContent = template.content;
this.attachShadow({ mode: 'open' }).appendChild(
templateContent.cloneNode(true)
);
}
}
customElements.define('my-todo-list',MyTodoList)
Les décorateurs TypeScript
TypeScript est une extension du langage JavaScript qui nous apporte le confort des contraintes. Etudions ce code JavaScript :
var i = 2 i = "hello"
Nous ne savons pas lors de l’écriture du code si la variable i est un nombre ou une chaine de caractères et cela peut être fatal si nous ne faisons pas l’effort de vérifier son type lors de son utilisation.
Avec TypeScript nous sommes contraints à garder le type défini lors de l’initialisation.
let i : number = 2 i = "hello" // Interdit
Cet exemple nous montre seulement un des aspects de TypeScript. Ce qui nous intéresse ici est l’apport des décorateurs.
Imaginons que nous souhaitions automatiser l’exécution de code pour deux classes différentes. Par exemple une classe Voiture et une classe Animal qui auraient toutes les deux leur table associée dans la base de données.
class Animal {
static {
// code pour initialiser la table ANIMAL
}
}
class Voiture {
static {
// code pour initialiser la table VOITURE
}
}
Dans cet exemple, difficile de mutualiser du code, nos classes ont un bloc d’initialisation static qui peut contenir de plus en plus de choses, difficile de maintenir, etc.
Avec les décorateurs TypeScript nous pouvons imaginer écrire nos classes différemment :
@CreateTable("ANIMAL")
class Animal {
}
@CreateTable("VOITURE")
class Voiture {
}
Et pourquoi pas leur ajouter d’autres fonctionnalités, par exemple l’utilisation d’un utilitaire de log différent :
@CreateTable("ANIMAL")
@Logger(SomeLogger)
class Animal {
}
@CreateTable("VOITURE")
@Logger(AnOtherLogger)
class Voiture {
}
Derrière ces décorateurs se cachent en fait de simples fonctions. Celles-ci ne sont exécutées qu’une fois au chargement de la classe, et non lors de nouvelles instances de celles-ci.
const CreateTable = (name: string) => {
return (target: Function) => {
console.log(name) // Le nom passé en paramètre, ici "ANIMAL"
console.log(target) // L'objet de type class, ici class Animal
console.log(Object.getOwnPropertyDescriptors(target.prototype)) // Liste des méthodes
};
};
@CreateTable("ANIMAL")
class Animal {
_age: number
get age(){ return this._age }
manger(){
//...
}
}
/*
ANIMAL
[class Animal]
{
constructor: {
value: [class Animal],
writable: true,
enumerable: false,
configurable: true
},
age: {
get: [Function: get age],
set: undefined,
enumerable: false,
configurable: true
},
manger: {
value: [Function: manger],
writable: true,
enumerable: false,
configurable: true
}
}
*/
Début d’un framework basé sur ces deux technologies
En combinant les Web Components et les décorateurs TypeScript, nous pouvons alors imaginer réaliser un début de framework maison inspiré d’Angular.
Avec Angular, la création d’un composant est déclarative, et son utilisation très simple depuis un fichier HTML :
@Component({
selector: 'app-my-component',
template: '{{ title }}
',
styles: ['h1 { font-weight: normal; }']
})
class MyComponent {
title = "Hello world"
}
Nous allons nous inspirer de cela pour écrire un début de framework. Nous avons besoin d’un décorateur qui va créer automatiquement son shadow DOM depuis le template passé dans les arguments du décorateur « Component ».
// Paramètres du décorateur
interface ComponentOptions {
selector: string; // Nom de la nouvelle balise
template: string; // Le template associé
style: string; // Un peu de css
}
// Fonction décorateur
function Component(options: ComponentOptions) {
return function < T extends { new (..._args: any[]): HTMLElement } >(
target: T
) {
const cls = class extends target {
constructor(..._args: any[]) {
super();
// Creation du shadow DOM
let root = this.attachShadow({ mode: "open" });
// Création des balises enfants avec EJS (moteur de template)
root.innerHTML = options.template;
// Ajout de style local
let style = document.createElement("style");
style.textContent = options.style;
root.appendChild(style);
}
};
// Enregistrement automatique en tant que custom element
customElements.define(options.selector, cls);
return cls;
};
}
@Component({
selector: "my-todo-list",
template: `
<%= title %>
- Do this
- Do that
Bien entendu, notre framework maison est encore loin d’être complet. Nous aurions besoin d’y ajouter une détection des changements, du routing, une couche HTTP, etc. Seule la partie de création de composants et d’affichage a été abordée dans cet article.