
Image générée avec ChatGPT
Introduction
Rappel sur le LLM
Un LLM (large language model) ou grand modèle de langage est un modèle de langage possédant un grand nombre de paramètres (ex: GPT-3 a 175 milliards de paramètres).Les LLMs sont des réseaux de neurones profonds entraînés sur de grandes quantités de données non étiquetées en utilisant l’apprentissage auto-supervisé ou l’apprentissage semi-supervisé, c’est à dire sans l’utilisation de données annotées par un humain ou un mélange de données annotées et non annotées. Les LLMs sont apparus vers 2018 et sont utilisés pour la mise en œuvre d’agents conversationnels, de traduction automatique, de résumé de texte, d’analyse des sentiments, de créations de contenu marketing etc. en générant du texte, des images, vidéos, sons, etc.
Ils prennent en entrée un prompt (texte, image ou vidéo si le LLM est multimodal).
En sortie ils génèrent également du texte, image ou vidéo. Ce sont des IA génératives.
La qualité du prompt est cruciale pour obtenir une bonne sortie du LLM.
Le LLM le plus connu et utilisé est ChatGPT qui a une utilisation gratuite restreinte et une partie payante très puissante, et peut être appelé avec une API REST et ainsi intégré dans une application existante.
Embeddings
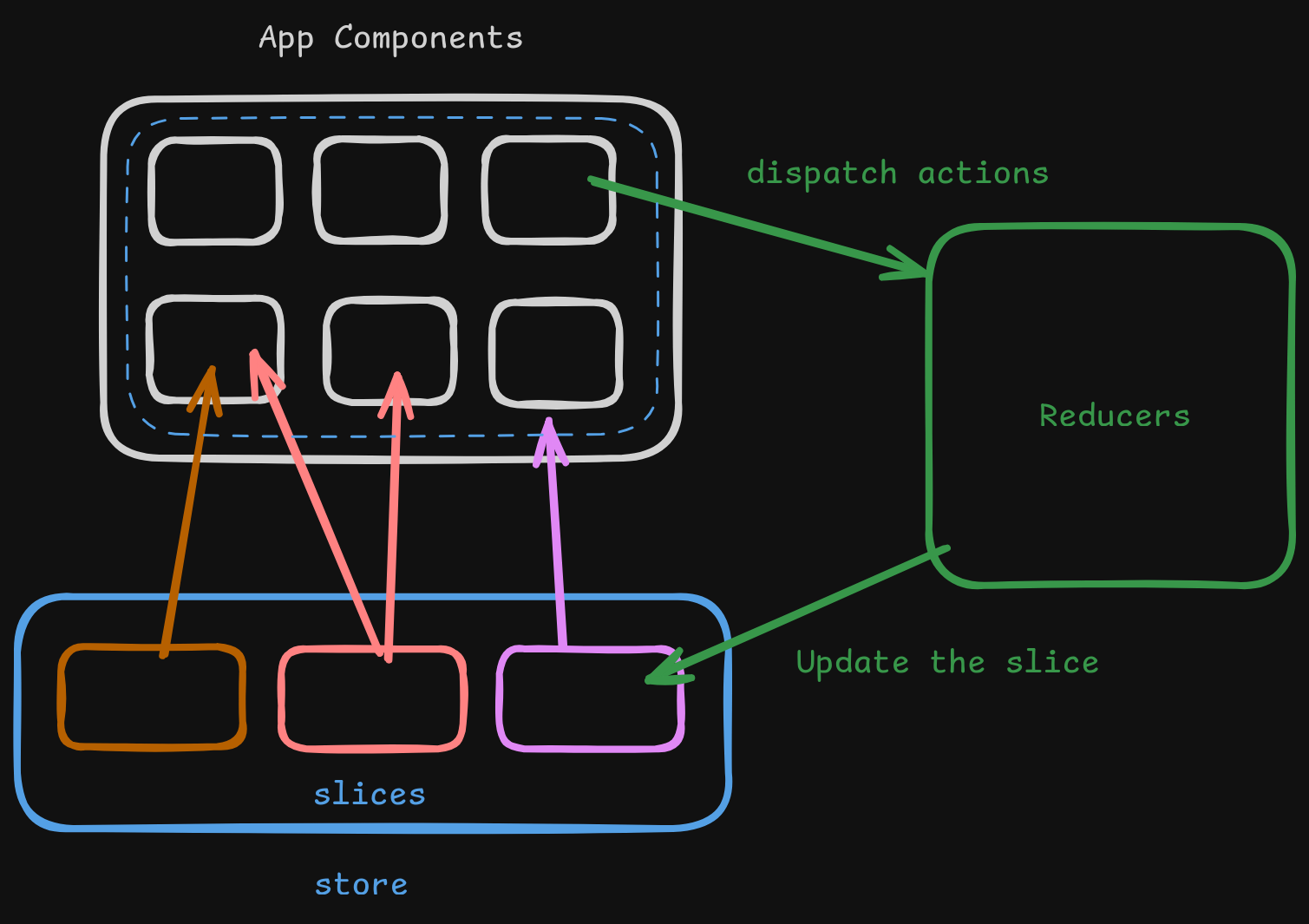
Pour que le modèle puisse comprendre et apprendre des données complexes comme du texte, des images ou des vidéos, celles-ci doivent d’abord être transformées en vecteurs numériques. C’est ce qu’on appelle des embeddings. Un embedding est une représentation vectorielle des données qui permet au modèle de comprendre les relations et significations des éléments d’entrée (comme le texte ou les images). Un modèle fait ainsi une relation par exemple entre « chat » et « félin » . Chaque élément est transformé en un vecteur numérique qui capture ses caractéristiques sémantiques. Ces vecteurs peuvent ensuite être utilisés pour effectuer des tâches comme la recherche d’informations ou la génération de réponses. Les données sont encodées et stockées dans le modèle.
Imaginez que vous devez trouver un livre spécifique dans une bibliothèque géante : l’embedding est comme le système de classification qui permet de retrouver rapidement le livre.
RAG
Certains modèles permettent de faire un RAG (Retrieval-Augmented-Generation) et ajouter le contenu de nos propres données pour générer ses réponses. Les données sont alors stockées dans une base de données vectorielle car comme le nom l’indique elle stocke les données encodés en vecteurs numériques et permet des recherches autour des termes du prompt. L’indexation approximative du plus proche voisin (ANN) est utilisé dans ces bases de données.
Un RAG a l’avantage de pouvoir utiliser ses propres données sans envoyer des informations confidentielles à un service tiers.
Un RAG est un supplément à l’inférence et il est particulièrement utile lorsque les informations nécessaires ne sont pas présentes dans les données d’entrainement du LLM car privées et/ou qu’on veut des données les plus récentes.
Le modèle tient en compte du contexte de la conversation pour répondre de façon cohérente et se souvient de ses réponses précédentes. Il a aussi des paramètres comme la température pour générer une réponse plus ou moins précise, inventive ou détaillée. Un modèle peut aussi halluciner et inventer complètement des données en sortie. Il est possible de régler cela au mieux à l’aide de son paramétrage et ainsi contrôler la qualité des réponses.
Il faut aussi se protéger contre les attaques par injection de prompt avec des Guardrails, stocker les clés d’API de manières sécurisées : variables d’environnement, gestionnaire de secrets, etc. et aussi faire de la modération au besoin.
Autant l’apprentissage, paramétrage et réglage du LLM demande énormément de données et de ressources, autant l’inférence, le fait d’utiliser un modèle, est permise sur un ordinateur de bureau. Plus votre processeur est puissant et plus votre RAM est grande, plus les modèles fonctionneront efficacement. Le LLM générera alors des réponses plus rapidement sur votre ordinateur.
LangChain4j
Maintenant que nous avons vu les principes de base des LLMs et de leurs usages, intéressons-nous à LangChain4j, un framework qui simplifie leur intégration dans des applications Java. LangChain4j permet de connecter facilement divers LLMs à des applications Java tout en offrant une flexibilité pour personnaliser le comportement du modèle selon les besoins. C’est la version java de LangChain qui lui est utilisé en Python et Javascript. En effet il y a une dominance des outils Python dans le domaine du LLM.
LangChain4j permet aux développeurs Java d’intégrer un LLM dans leur code existant, grâce notamment à l’intégration avec Spring Boot, Quarkus, etc. Il permet d’utiliser des modèles open source localement et donc de ne pas envoyer ses prompts contenant des informations confidentielles comme du code propriétaire ou bien les questions privées des clients et des personnes de l’entreprise.
Les développeurs ont commencé à créer LangChain4j début 2023, au moment de la hype autour de ChatGPT. Il manquait une alternative en Java aux nombreuses bibliothèques Python et Javascript et LangChain4j répond à un besoin des développeurs Java.
Le code hébergé sur github est actuellement en version 1.0.1 et a 7.7k stars et 1.4k forks. LangChain4j propose de nombreux exemples et tutoriels pour apprendre à l’utiliser.
La communauté LangChain4j est importante pour obtenir de l’aide et partager ses expériences.
LangChain4j permet d’intégrer + de 15 LLMs populaires, certains payants, ou bien d’utiliser des modèles en local pour créer par exemple un chatbot pour un support client, générer du contenu marketing, un assistant virtuel ou encore une application de dialogue automatique. Et cela sans se soucier de la complexité sous-jacente.
Nous pouvons entre autres utiliser OpenAI, Mistral AI, Google Gemini, etc. grâce à leurs API payantes et API Keys mais aussi utiliser Ollama ou JLama qui font tourner des LLMs en local, et sont gratuits.
LangChain4j permet également de réaliser un RAG (Retrieval-Augmented Generation) et d’utiliser vos propres fichiers (txt, PDF, Microsoft Office) avec le modèle sélectionné.
Ainsi, des questions portant sur des données privées peuvent recevoir une réponse contenue dans ces fichiers par le chatbot.
Installation de LangChain4j
Intégration de la librairie
via Maven (dans le pom.xml)
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0</version>
</dependency>
via Gradle (dans le build.gradle)
implementation 'dev.langchain4j:langchain4j-open-ai:1.0.0' implementation 'dev.langchain4j:langchain4j:1.0.0'
Ces dépendances Maven/Gradle permettent d’ajouter LangChain4j à votre projet Java. langchain4j-open-ai est la bibliothèque spécifique pour utiliser les modèles d’OpenAI, tandis que langchain4j est la bibliothèque de base. Vous pouvez utiliser le framework et ajouter d’autres modèles selon vos besoins. Vous intégrez aussi embeddings, transformers, parsers de documents, ainsi que des frameworks comme Spring Boot ou Quarkus.
Exemple d’utilisation de OpenAI
Le code définit la question « en dur » et fournit une réponse simple.
Ça présente un exemple de question et sa réponse par le modèle OpenAI.
C’est un exemple « basique ».
import static dev.langchain4j.model.openai.OpenAiChatModelName.GPT_4_O_MINI;
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY")) // clé privée de l'API, "demo" pour test
.modelName(GPT_4_O_MINI) // nom de l'API, ici ""gpt-4o-mini"
.build();
try {
String answer = model.chat("Say Hello World");
System.out.println(answer);
} catch (Exception e) {
System.err.println(e.getMessage());
}
--> "Hello World"
Utilisation de Ollama en local
L’application utilise Ollama via son API REST via http://localhost:11434.
Vous lancez Ollama sur la machine ou dans un conteneur Docker.. Il télécharge ensuite le modèle au besoin.
Il propose par défaut un prompt texte et répond aux questions en entrée en utilisant le modèle choisi.
Ici nous l’utilisons dans notre programme Java de manière transparente. Ollama peut tourner sur notre machine ou une machine distante.
Exemple d’utilisation de Ollama avec le modèle llma3.1
ollama run llama3.1
Exemple de création d’un chatbot avec Ollama
private final static String BASE_URL = "http://localhost:11434";
private final static String MODEL_NAME = "llama3.1";
public static void main(String[] args) throws Exception {
ChatModel chatModel = OllamaChatModel.builder()
.baseUrl(BASE_URL)
.modelName(MODEL_NAME)
.logRequests(true)
.build();
try (Scanner scanner = new Scanner(System.in)) {
String prompt = "";
do {
System.out.print("Prompt: ");
prompt = scanner.nextLine();
String answer = chatModel.chat(prompt);
System.out.println(answer);
} while (!prompt.isEmpty());
}
}
Utilisation de JLama
Le processus Java charge le modèle en mémoire.
JLama maintient une liste de modèles populaires pré-quantifiés sur http://huggingface.co/tjake. Vous en choisissez un, et l’outil le télécharge automatiquement sur votre machine.
Il suffit de créer le ChatModel en passant le nom du modèle en paramètre.
Exemple de création d’un chatbot avec JLama
public static void main(String[] args) throws Exception {
ChatModel model = JlamaChatModel.builder()
.modelName("tjake/Llama-3.2-1B-Instruct-JQ4")
.temperature(0.3f)
.build();
try ( Scanner scanner = new Scanner( System.in ) ) {
System.out.println("What is the context?");
String context = scanner.nextLine();
String prompt = "";
do {
System.out.print("Prompt: ");
prompt = scanner.nextLine();
ChatResponse chatResponse = model.chat(
SystemMessage.from(context),
UserMessage.from(prompt)
);
System.out.println("\n" + chatResponse.aiMessage().text() + "\n");
} while (!prompt.isEmpty() && !prompt.equals("exit"));
}
}
Utilisation d’un RAG avec JLama
Le RAG (Retrieval-Augmented Generation) combine l’extraction d’informations avec la génération de texte. L’idée est de récupérer des informations pertinentes d’une base de données (par exemple, un fichier texte) et de les utiliser pour générer une réponse plus précise et contextuelle. Ce processus est particulièrement utile lorsqu’un modèle doit répondre à des questions basées sur des informations spécifiques qui ne sont pas dans ses paramètres d’entraînement.

L’application charge le fichier texte « documents/biography-of-john-doe.txt » depuis les ressources. Le modèle répond ensuite aux questions dont les réponses se trouvent dans ce fichier.
Il y a différentes façon de coder l’utilisation d’un RAG. Ici nous présentons la méthode « facile ».
Sachez qu’il y a la possibilité de coder plus précisément l’intégration de la ressource (texte, pdf ou fichier Microsoft Office) selon notre besoin.
IAiServices construit un Assistant (Interface définie dans notre code) pour discuter avec le modèle choisi.
Le .chatMemory(MessageWindowChatMemory.withMaxMessages(10)) permet au chat de se souvenir des 10 derniers messages lorsqu’il génère une réponse.
Le modèle pourra ainsi répondre à la question : « Quel est le nom de la femme de John Doe ? ».
public interface Assistant {
String answer(String query);
}
public static void main(String[] args) throws Exception {
URL resource = JlamaBasicRagEmbedExample.class.getClassLoader().getResource("documents/biography-of-john-doe.txt");
// Load a single document
Document document = FileSystemDocumentLoader.loadDocument(resource.getPath(), new ApacheTikaDocumentParser());
ChatModel chatModel = JlamaChatModel.builder()
.modelName("tjake/Llama-3.2-1B-Instruct-JQ4")
.temperature(0.2f) // expect a more focused and deterministic answer
.build();
// Second, let's create an assistant that will have access to our documents
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10)) // it should remember 10 latest messages
.contentRetriever(createContentRetriever(List.of(document))) // it should have access to our documents
.build();
// Lastly, let's start the conversation with the assistant. We can ask questions like:
// - Who is John Doe's wife?
startConversationWith(assistant);
}
public static void startConversationWith(Assistant assistant) {
try (Scanner scanner = new Scanner(System.in)) {
while (true) {
System.out.println("==================================================");
System.out.println("User: ");
String userQuery = scanner.nextLine();
System.out.println("==================================================");
if ("exit".equalsIgnoreCase(userQuery) || userQuery.isEmpty()) { break; }
String agentAnswer = assistant.answer(userQuery);
System.out.println("==================================================");
System.out.println("Assistant: " + agentAnswer);
}
}
}
private static ContentRetriever createContentRetriever(List<Document> documents) {
// Here, we create an empty in-memory store for our documents and their embeddings.
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// Here, we are ingesting our documents into the store.
// Under the hood, a lot of "magic" is happening, but we can ignore it for now.
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
// Lastly, let's create a content retriever from an embedding store.
return EmbeddingStoreContentRetriever.from(embeddingStore);
}
Avantages et inconvénients de chaque approche
OpenAI propose des modèles puissants, mais nécessite une clé API et des crédits. Il est idéal si vous avez besoin d’un modèle très performant avec un support fiable.
Ollama est gratuit et fonctionne localement. Il est idéal pour les applications où l’autonomie et la confidentialité des données sont cruciales.
JLama permet de charger et d’utiliser des modèles préquantifiés depuis HuggingFace. Cela permet une grande flexibilityé mais nécessite plus de ressources locales pour l’inférence.
Sécurité et fiabilité
Évitez de coder la température trop basse pour les réponses créatives mais précises.
Utilisez des mémoires conversationnelles avec déclinaison par fenêtre ou token récent pour maintenir l’efficacité du modèle. Cela permet de respecter le contexte limité par la RAM.
Intégrez toujours une couche de validation des entrées utilisateur avant traitement.
Conclusion
En conclusion, LangChain4j facilite l’intégration des LLMs dans les applications Java de manière simple et efficace. Vous pouvez choisir une API payante comme OpenAI. Vous pouvez aussi utiliser un modèle local avec Ollama. Une solution flexible comme JLama constitue également une option intéressante. Selon vos besoins en performance et en ressources, explorez ces alternatives pour trouver celle qui conviendra le mieux.
Selon les benchmarks, l’infrastructure requise pour exécuter un LLM localement dépend du modèle choisi :
- les modèles comme Ollama ou JLama nécessitent généralement 8Go à 16Go de RAM minimum,
- pour améliorer les performances avec les modèles volumineux, utilisez un GPU si disponible via NVIDIA CUDA ou AMD ROCm. Vous pouvez aussi employer une carte matérielle spécialisée en IA afin d’obtenir de meilleurs résultats.
Les frameworks comme LangChain4j et JLama aident les développeurs Java à exploiter les récentes avancées en intelligence artificielle. Ils leur permettent de bénéficier de ces progrès sans avoir à gérer la complexité du matériel sous-jacent. Vous pouvez ainsi vous concentrer sur la logique métier tout en bénéficiant d’une intelligence artificielle performante.
Au-delà de ces bénéfices immédiats, plusieurs tendances se dessinent dans l’écosystème :
- le développement de bots intelligents reposant sur des agents conversationnels et autonomes,
- le recours croissant au fine-tuning pour adapter les modèles à des domaines spécifiques,
- et l’émergence d’applications Java combinant API cloud et calcul local en fonction des besoins.










 Connecting low power IoT devices with LoRa, MQTT, and The Things Network
Connecting low power IoT devices with LoRa, MQTT, and The Things Network






 réseau mondial et libre permettant la collecte et l’échange de données provenant d’objets connectés.
réseau mondial et libre permettant la collecte et l’échange de données provenant d’objets connectés.





{kind=link}
{kind=link}