Introduction
Le but de cet article est de présenter brièvement le concept de DevOps, illustré par une implémentation concrète dans un environnement applicatif de microservices Restfull, développés dans le contexte d’une approche agile.
La première partie est consacrée au rappel des principes de DevOps et à la présentation du schéma architectural d’une chaîne DevOps avec Github, Jenkins, Artifactory et Ansible.
Cette deuxième partie présente une autre chaîne DevOps avec Github, Jenkins, Artifactory et OpenShift.
1 Exemple d’une mise en oeuvre avec OpenShift
La chaîne DevOps décrite ci-dessous permet d’assurer des déploiements dans une plateforme de containers (OpenShift) sur différents namespaces (§. 1.1 ci-dessous) : INT, VAL et PROD.
Elle est composée des éléments suivants :
- GitHub
- Git local installé sur chaque poste développeur
- OpenShift qui héberge différents namespaces. Dans chaque namespace, un pod Jenkins pilote les builds (compilation/packaging) et le déploiement
- Artifactory : repository des artifacts
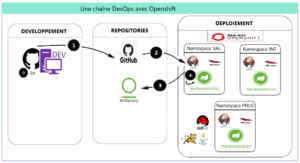

Dans ce cas d’utilisation, tout se passe dans OpenShift, plateforme de containers. La plateforme est structurée en namespaces. Chaque namespace correspond à un environnement technique d’un projet (VAL, INT, PROD, …).
Chaque namespace (§. 1.1 ci-dessous) dispose de son propre pod Jenkins. Celui-ci exécute, à chaque update du projet dans Github (déclenchement par webhook), un job de type pipeline qui comporte plusieurs phases (stages) :
-
- Git clone du repository Github
- Build par maven (compilation –> tests unitaires –> tests intégration –> packaging)
- Audit du code par sonar
- Déploiement exécuté en fonction d’une build configuration et d’une deployment configuration (§. 1.1 ci-dessous)
- Création d’une image docker à partir des sources de l’application
- Création d’un pod (host exécutant le microservice) incluant le container de cette image
- Génération du service, interface externe correspondant aux différents pods d’une application, et joue le rôle de répartiteur de charge
- Génération des routes qui permettent d’accéder au service d’un pod
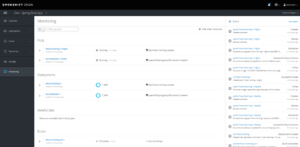
Exemple d’un dashboard de pipeline Jenkins, illustré ci-dessous :

Par ailleurs, OpenShift assure d’autres fonctionnalités opérationnelles :
- Il gère les variations de charge de l’application par l’intermédiaire d’un replication controller: ajuste le nombre d’instances d’un pod en fonction de la charge.
- Il assure le monitoring des applications qu’il héberge
- Il gère les logs : logs des builds et logs applicatifs
- Il permet via une interface Web d’accéder et d’administrer toutes ces fonctionnalités (§. 1.3 ci-dessous)
1.1 Notion de namespace dans OpenShift
La notion de namespace dans OpenShift vient de Kubernetes dont il est une sur-couche. Elle permet de regrouper dans un même espace de nommage les ressources qui décrivent une application et comment elle doit être déployée. La figure ci-dessous regroupe tous les éléments qui constituent un namespace :
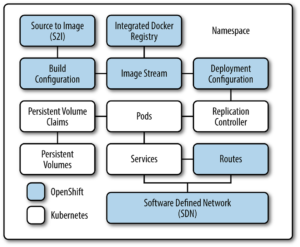
Contrairement à Kubernetes qui permet d’accéder à tous les namespaces d’un cluster, OpenShift encapsule chaque namespace dans un projet qui va permettre d’en contrôler les accès par un modèle d’authentification et d’autorisations basé sur les users et les groups.
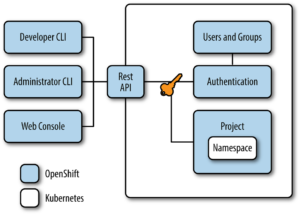
Il existe 3 canaux pour interagir avec un cluster Openshift à travers son API Rest : une CLI (ligne de commande) oc, une interface Web et l’API elle-même. Plus de détails dans la documentation OpenShift.
1.2 CLI (Ligne de commande) OpenShift
L’objet de ce document n’étant pas d’exposer en détail le fonctionnement d’OpenShift, on se contentera de montrer ci-dessous quelques vues du déploiement d’un service de base de données PostgreSql en exécutant des commandes oc. Dans le paragraphe suivant, on verra les vues relatives à ce service dans la console Web.
- Déploiement d’une base PostgreSql
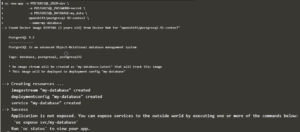
- Affichage de la description du déploiement dc/my-database, créé par la commande précédente :
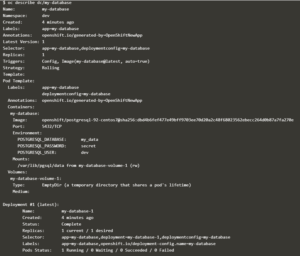
1.3 Console web OpenShift
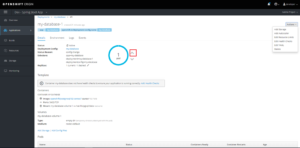
Ci-dessous, quelques vues dans la console Web relatives au déploiement décrit dans le paragraphe précédent :
- Description du déploiement dc/my-database : on voit une représentation du pod correspondant. Les flèches haut/bas (encadrée en rouge) permettent d’augmenter/diminuer manuellement le nombre d’instances du pod.
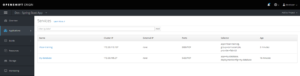
- Vue des services : Outre le service my-database, on distingue un autre service, (microservice springboot) déployé qui utilise le service my-database
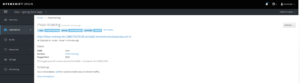
- Vue d’une route (URL) pour accéder au microservice :
- Vue du monitoring :
En résumé
Dans cet article ont été rappelés les concepts de DevOps en relation avec une approche agile du développement d’applications. Deux schémas architecturaux de chaînes DevOps sont présentés ayant en commun les outils de versionning et de repositories (GitHub et Artifactory) ainsi que Jenkins comme pilote de l’intégration et du déploiement continus.
Dans cette deuxième partie, la chaîne DevOps présentée utilise OpenShift. Celui-ci joue les rôles à la fois d’une plateforme de containers et d’un cloud privé. A travers la notion de namespace encapsulé dans un projet, il gère les aspects droits d’accès, cycle de vie des applications, répartition de charges, gestion des logs et monitoring.
La première partie de cet artice est consacrée à la présentation d’une autre chaîne DevOps. Elle utilise Ansible pour exécuter les déploiements sur les différents nœuds et environnements de l’application. Ansible est installé sur un nœud unique et permet via les playbooks et son interface Ansible Tower d’automatiser le processus de déploiement sur un grand nombre de nœuds (serveurs, périphériques, …).
The point of view of your article has taught me a lot, and I already know how to improve the paper on gate.oi, thank you. https://www.gate.io/pt-br/signup/XwNAU
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.