By Eric Descargues/1 septembre 2020/Commentaires fermés sur Agrément CIR renouvelé pour DocDoku jusqu’en 2027
Agrément CIR depuis 2011
Pour la cinquième fois consécutive, DocDoku obtient son agrément Crédit d’Impôt Recherche (CIR) pour quatre ans, jusqu’en 2027 donc. Nous détenons en effet cet agrément depuis 2011.
Pour rappel, cela signifie que DocDoku est reconnu comme organisme ayant la capacité à mener des travaux de Recherche et Développement (R&D) et que toutes les dépenses de réalisation d’opérations de R&D confiées à DocDoku ouvrent droit au Crédit d’Impôt en faveur de la Recherche, dans les mêmes conditions que pour des investissements internes.
Le CIR, c’est quoi ?
Pour rappel, le CIR est un dispositif d’incitation fiscale en faveur de la recherche et de l’innovation. Il permet aux entreprises de bénéficier d’un crédit d’impôt correspondant à un pourcentage du montant des dépenses investies dans l’année en recherche et développement. Cet avantage fiscal varie entre 30% et 50% de Crédit d’Impôt sur les dépenses engagées pour les projets éligibles (voir conditions sur le site du Ministère).
Qu’attendons-nous pour innover ensemble ?
Qu’attendez-vous pour innover et lancer de nouveaux projets R&D puisque ces derniers peuvent faire l’objet d’une prise en charge substantielle au travers du Crédit d’Impôt Recherche lorsque vous passez par notre intermédiaire ?
Pour toutes questions sur vos projets innovants, contactez-nous.
Le but de cet article est de présenter brièvement le concept de DevOps, illustré par une implémentation concrète dans un environnement applicatif de microservices Restfull, développés dans le contexte d’une approche agile.
La première partie est consacrée au rappel des principes de DevOps et à la présentation du schéma architectural d’une chaîne DevOps avec Github, Jenkins, Artifactory et Ansible.
Cette deuxième partie présente une autre chaîne DevOps avec Github, Jenkins, Artifactory et OpenShift.
1 Exemple d’une mise en oeuvre avec OpenShift
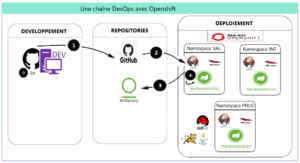
La chaîne DevOps décrite ci-dessous permet d’assurer des déploiements dans une plateforme de containers (OpenShift) sur différents namespaces (§. 1.1 ci-dessous) : INT, VAL et PROD.
Elle est composée des éléments suivants :
GitHub
Git local installé sur chaque poste développeur
OpenShift qui héberge différents namespaces. Dans chaque namespace, un pod Jenkins pilote les builds (compilation/packaging) et le déploiement
Artifactory : repository des artifacts
Dans ce cas d’utilisation, tout se passe dans OpenShift, plateforme de containers. La plateforme est structurée en namespaces. Chaque namespace correspond à un environnement technique d’un projet (VAL, INT, PROD, …).
Chaque namespace (§. 1.1 ci-dessous) dispose de son propre pod Jenkins. Celui-ci exécute, à chaque update du projet dans Github (déclenchement par webhook), un job de type pipeline qui comporte plusieurs phases (stages) :
Déploiement exécuté en fonction d’une build configuration et d’une deployment configuration (§. 1.1 ci-dessous)
Création d’une image docker à partir des sources de l’application
Création d’un pod (host exécutant le microservice) incluant le container de cette image
Génération du service, interface externe correspondant aux différents pods d’une application, et joue le rôle de répartiteur de charge
Génération des routes qui permettent d’accéder au service d’un pod
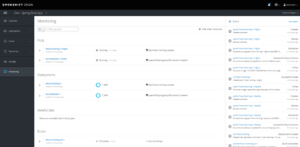
Exemple d’un dashboard de pipeline Jenkins, illustré ci-dessous :
Par ailleurs, OpenShift assure d’autres fonctionnalités opérationnelles :
Il gère les variations de charge de l’application par l’intermédiaire d’un replication controller: ajuste le nombre d’instances d’un pod en fonction de la charge.
Il assure le monitoring des applications qu’il héberge
Il gère les logs : logs des builds et logs applicatifs
Il permet via une interface Web d’accéder et d’administrer toutes ces fonctionnalités (§. 1.3 ci-dessous)
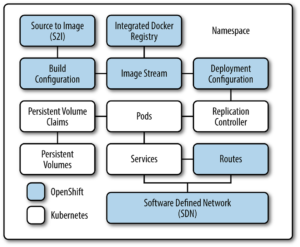
1.1 Notion de namespace dans OpenShift
La notion de namespace dans OpenShift vient de Kubernetes dont il est une sur-couche. Elle permet de regrouper dans un même espace de nommage les ressources qui décrivent une application et comment elle doit être déployée. La figure ci-dessous regroupe tous les éléments qui constituent un namespace :
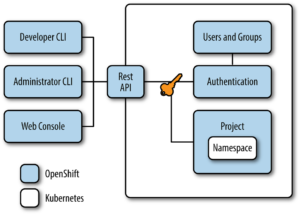
Contrairement à Kubernetes qui permet d’accéder à tous les namespaces d’un cluster, OpenShift encapsule chaque namespace dans un projet qui va permettre d’en contrôler les accès par un modèle d’authentification et d’autorisations basé sur les users et les groups.
Il existe 3 canaux pour interagir avec un cluster Openshift à travers son API Rest : une CLI (ligne de commande) oc, une interface Web et l’API elle-même. Plus de détails dans la documentation OpenShift.
1.2 CLI (Ligne de commande) OpenShift
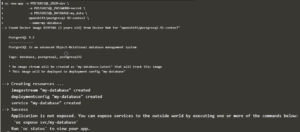
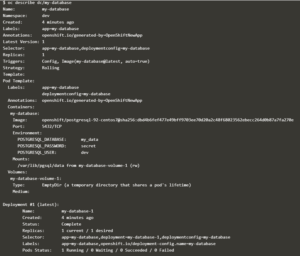
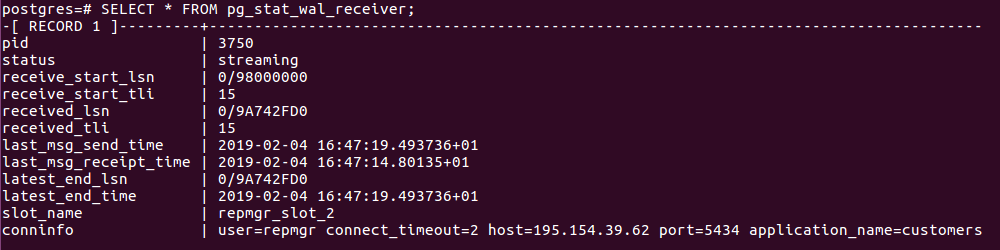
L’objet de ce document n’étant pas d’exposer en détail le fonctionnement d’OpenShift, on se contentera de montrer ci-dessous quelques vues du déploiement d’un service de base de données PostgreSql en exécutant des commandes oc. Dans le paragraphe suivant, on verra les vues relatives à ce service dans la console Web.
Déploiement d’une base PostgreSql
Affichage de la description du déploiement dc/my-database, créé par la commande précédente :
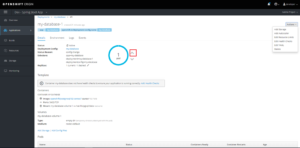
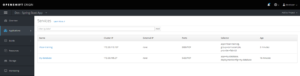
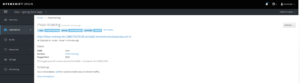
1.3 Console web OpenShift
Ci-dessous, quelques vues dans la console Web relatives au déploiement décrit dans le paragraphe précédent :
Description du déploiement dc/my-database : on voit une représentation du pod correspondant. Les flèches haut/bas (encadrée en rouge) permettent d’augmenter/diminuer manuellement le nombre d’instances du pod.
Vue des services : Outre le service my-database, on distingue un autre service, (microservice springboot) déployé qui utilise le service my-database
Vue d’une route (URL) pour accéder au microservice :
Vue du monitoring :
En résumé
Dans cet article ont été rappelés les concepts de DevOps en relation avec une approche agile du développement d’applications. Deux schémas architecturaux de chaînes DevOps sont présentés ayant en commun les outils de versionning et de repositories (GitHub et Artifactory) ainsi que Jenkins comme pilote de l’intégration et du déploiement continus.
Dans cette deuxième partie, la chaîne DevOps présentée utilise OpenShift. Celui-ci joue les rôles à la fois d’une plateforme de containers et d’un cloud privé. A travers la notion de namespace encapsulé dans un projet, il gère les aspects droits d’accès, cycle de vie des applications, répartition de charges, gestion des logs et monitoring.
La première partie de cet artice est consacrée à la présentation d’une autre chaîne DevOps. Elle utilise Ansible pour exécuter les déploiements sur les différents nœuds et environnements de l’application. Ansible est installé sur un nœud unique et permet via les playbooks et son interface Ansible Tower d’automatiser le processus de déploiement sur un grand nombre de nœuds (serveurs, périphériques, …).
Saviez-vous que la technologie Blockchain proposait des solutions concrètes pour :
Assurer la véracité et la pertinence de vos données
Obtenir une vision globale de votre chaîne de valeur
Coordonner parfaitement des process Métier hétérogènes
Trouver des solutions à la complexité et l’étendue de votre Supply Chain ?
La Team DocDoku vous propose de partager son éclairage sur les usages concrets de la Blockchain au cours d’un petit déjeuner le Vendredi 18 octobre 2019 à partir de 8h30. Commencez votre journée en découvrant comment la Blockchain peut se mettre au service de votre Métier, au travers de cas d’usage concrets mais également de best practices métier et techniques.
Programme
8h30-9h : Accueil
9h-9h15 : Définir la Blockchain et identifier les projets « Blockchain ready »
9h15-9h45 : Découvrir un usage de la Blockchain dans l’Aéronautique (MRO)
9h45-10h00 : Comprendre les enjeux techniques
10h00-10h15 : Réflexions et perspectives
10h15-10h30 : Echanges avec les participants
Accès libre sur inscription réservé aux acteurs de l’innovation (CTO, DSI, Responsable Métier, R&D, Data…)
Informations pratiques
Quand ? Vendredi 18 octobre de 8h30 à 10h30
Où ? Chez DocDoku, 76 allée Jean Jaurès, 31 000 Toulouse
Par soucis de « vulgarisation » et d’accessibilité au plus grand nombre, certains concepts clés évoqués dans cet article ont été « simplifiés » ou « raccourcis ». Il conviendra à chacun d’étoffer sa recherche à l’aide des liens fournis dans la rubrique « Ressources ».
Généralement, les présentations autour de Bitcoin commencent par une approche théorique des mécanismes permettant de sécuriser le réseau.
Dans cette présentation nous allons faire abstraction de tout cela → ?.
Nous allons considérer la blockchain Bitcoin comme un service de stockage décentralisé que l’on va exploiter en mode Blockchain As a Service.
Nous consommerons ce service à l’aide de la librairie NBitcoin.net et de l’api QBitNinja.
Nous auront une approche pratique, qui consistera à programmer et signer un transfert Bitcoin entre deux adresses que nous allons créer.
La notion de « transfert » et de « vérification de propriété » est fondamentale pour le réseau Bitcoin puisqu’il à été spécialement conçu pour cela !
Tout en construisant notre transfert, nous découvrirons notamment à quoi servent une adresse, une clé privé, une clé publique et une transaction …
Généralités sur Bitcoin
Un système de transfert et de vérification de propriété,
Repose sur un réseau pair à pair,
Pas d’autorité centrale,
L’application initiale et l’innovation principale de ce réseau est un système de monnaie numérique décentralisé,
L’unité de compte au sein du réseau Bitcoin est nommée « Bitcoin »,
Bitcoin fonctionne avec des logiciels et un protocole,
Permet à ses participant d’émettre et de gérer des transactions de façon collective et automatique,
Un protocole libre et ouvert dont le code source est publié sous licence MIT,
Bitcoin est conçu pour s’auto-réguler,
Son bon fonctionnement est garanti par une organisation générale que tout le monde peut examiner,
Tout y est public : protocoles de base, algorithmes cryptographiques, programmes opérationnels, données de comptes, débats des développeurs …
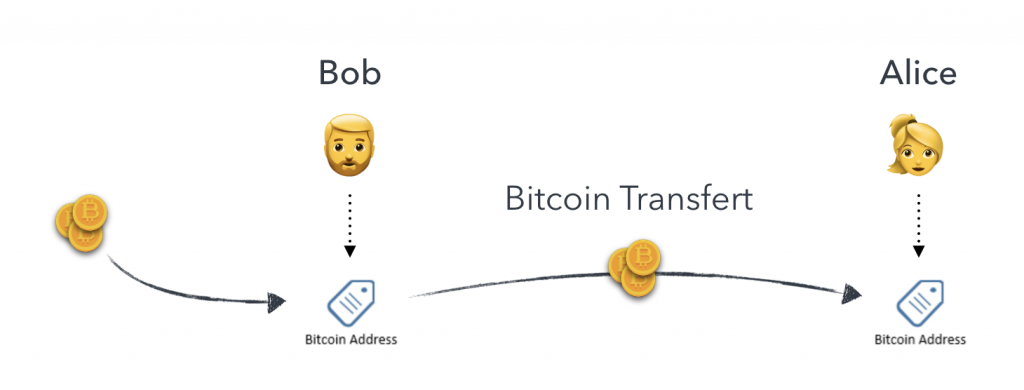
Bitcoin Transfert : Problématique
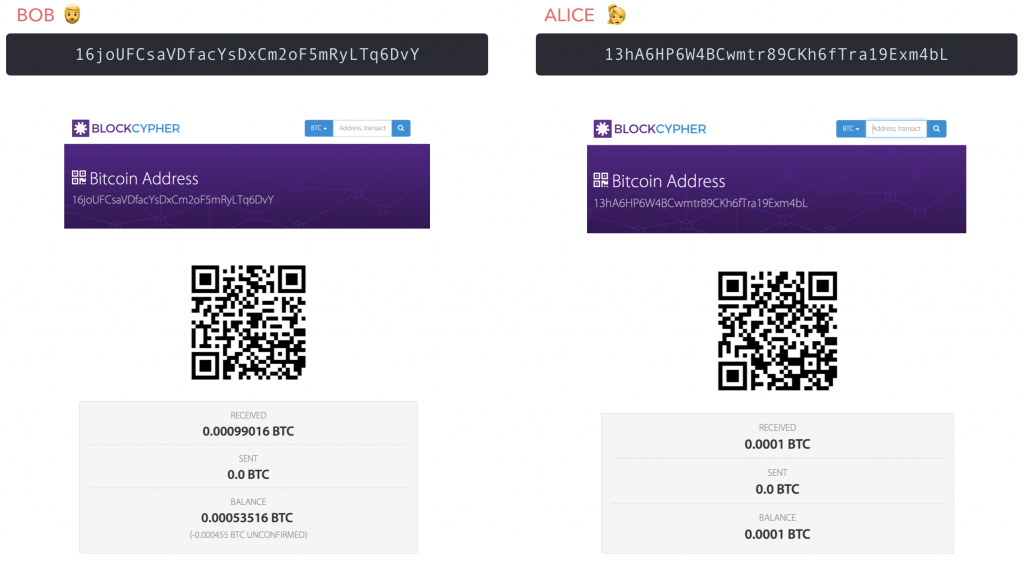
Des fonds initiaux ont été envoyés à Bob,
Bob à réalisé un transfert de Bitcoin à Alice en lui laissant un message,
Nous allons recréer la transaction entre Bob et Alice à l’aide de NBitcoin,
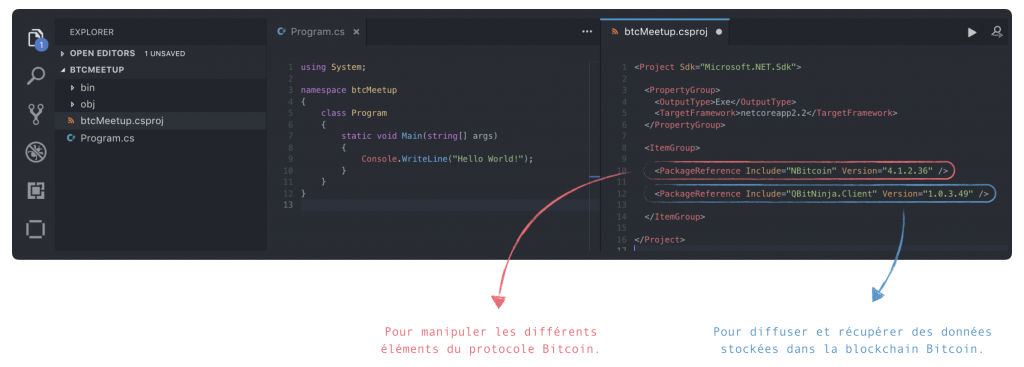
Configuration du projet (.netCore + VSCode)
Auteur de NBitcoin et QBitNinja.Client : Nicolas Dorier, METACO SA
$ mkdir btcMeetup
$ cd btcMeetup
$ dotnet new console
$ dotnet add package NBitcoin
$ dotnet add package QBitNinja.Client
$ dotnet restore
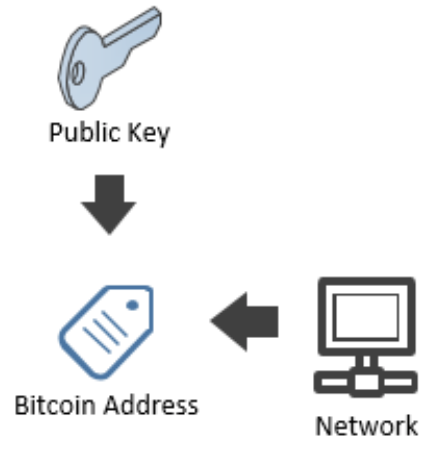
Eléments fondamentaux
Pour réaliser un transfert sur le protocole Bitcoin, on s’appuie sur 5 éléments fondamentaux :
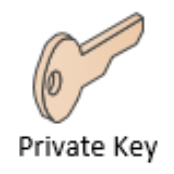
Private Key :
Permet de signer une transaction,
Donne le droit de dépenser les fonds liés à une adresse,
Ne doit pas être partagé, doit être conservé en lieu sûr.
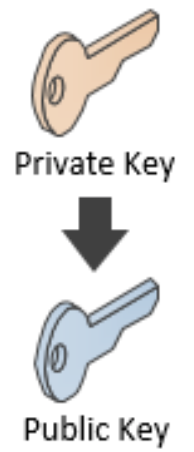
Public Key :
Permet de s’assurer que vous êtes le propriétaire d’une adresse pouvant recevoir des fonds,
Est générée à partir de la clé privée (l’inverse étant « impossible ») Permet de s’assurer que vous êtes le propriétaire d’une adresse pouvant recevoir des fonds,
La clé public permet de générer une adresse bitcoin et un scriptPubKey.
ScriptPubKey :
C’est un peu l’équivalent d’une BitcoinAddress mais au niveau du protocole.
Vous n’envoyez donc pas des fonds à une adresse mais à un ScriptPubKey.
N’est pas facilement partageable contrairement à une adresse.
Bitcoin Address :
Pour recevoir un transfert de fonds,
Information facilement encodable en QR Code,
Peut être communiquée à tout le monde.
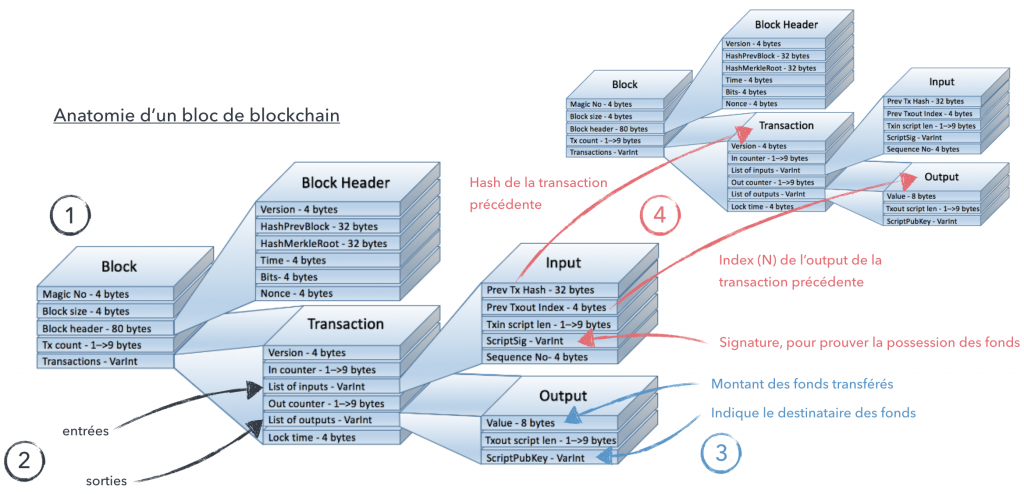
Transaction :
Structure de données permettant d’encoder un transfert de valeur entre un ou plusieurs participants au réseau Bitcoin.
Générer une adresse pour Bob et une adresse pour Alice
Une adresse Bitcoin est une information que vous allez partager avec les autres utilisateurs du réseau pour recevoir des fonds.
Mais pour obtenir une adresse vous devez d’abord générer une clé privée !
Elle est le seul moyen de dépenser les bitcoins envoyés à votre adresse.
Les clés privées sont personnelles et ne sont pas stockées sur le réseau.
Elles peuvent être générées sans être connectées à internet.
NBitcoin supporte plusieurs standards pour générer des clés privées …
Nous allons utiliser les standards BIP32 et BIP39 qui permettent de générer une clé racine à partir d’une wordlist. C’est sur ce principe que fonctionnent les cold-wallets tel que Ledger Nano ou Trezor. Cette wordlist ou seed ou mnemonic permet de re-générer indéfiniment la même suite de clé.
Ci-après le processus de génération de clés que nous allons suivre :
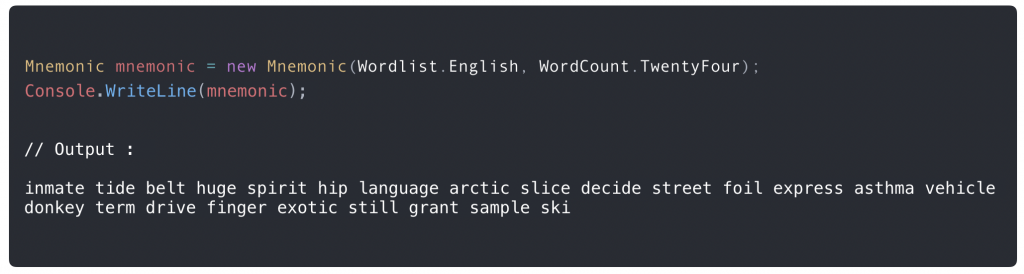
Etape 1 : Générer une nouvelle mnémonique :
Etape 1 (bis) : Restaurer une mnémonique existante :
Etape 2 : On génère la clé racine qui dérive de notre « Mnémonique » et d’un mot de passe :
Etape 3 : On peut maintenant générer deux « sous-clés », une pour Bob, une pour Alice, en dérivant de notre clé racine :
Remarque : Grâce à ce mécanisme de dérivation, il est possible de générer et régénérer des arborescences complexes de clés. On peut par exemple construire une arborescence de clés basées sur l’organigramme d’une entreprise.
Etape 4 : A partir de nos deux clés privées, nous allons pouvoir obtenir leurs clés publiques respectives :
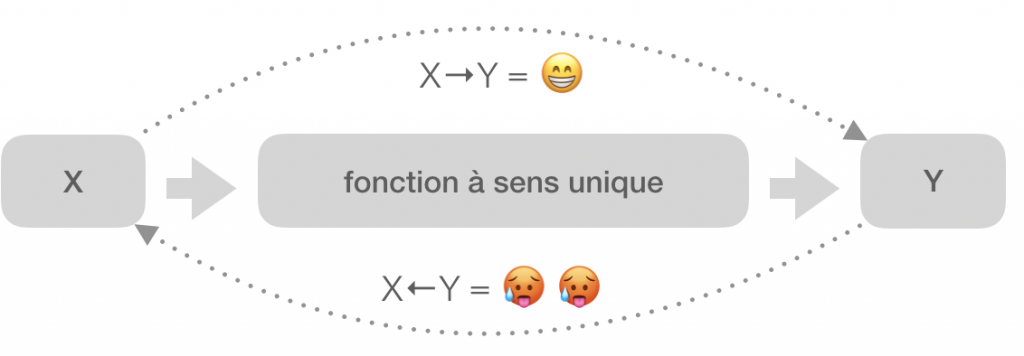
On génère une clé publique à partir d’une clé privée au moyen d’une fonction à sens unique.
C’est à dire une fonction qui peut aisément être calculée mais difficilement inversée.
La clé publique permet de recevoir des fonds et d’attester que vous être le propriétaire d’une adresse.
En revanche, elle ne permet pas de dépenser les fonds d’une adresse.
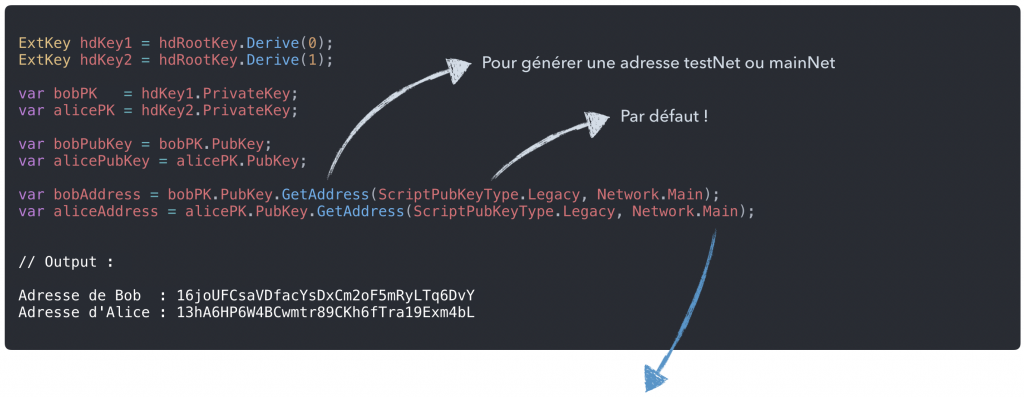
Etape 5 : Après avoir généré les clés publiques d’Alice et Bob, nous allons pouvoir obtenir leurs adresses :
Il existe 2 réseaux Bitcoins : MainNet et TestNet,
On obtient une adresse Bitcoin à partir de sa clé publique, et en précisant le réseau sur lequel on souhaite opérer.
Remarque: sur le MainNet, les erreurs peuvent coûter cher ? !
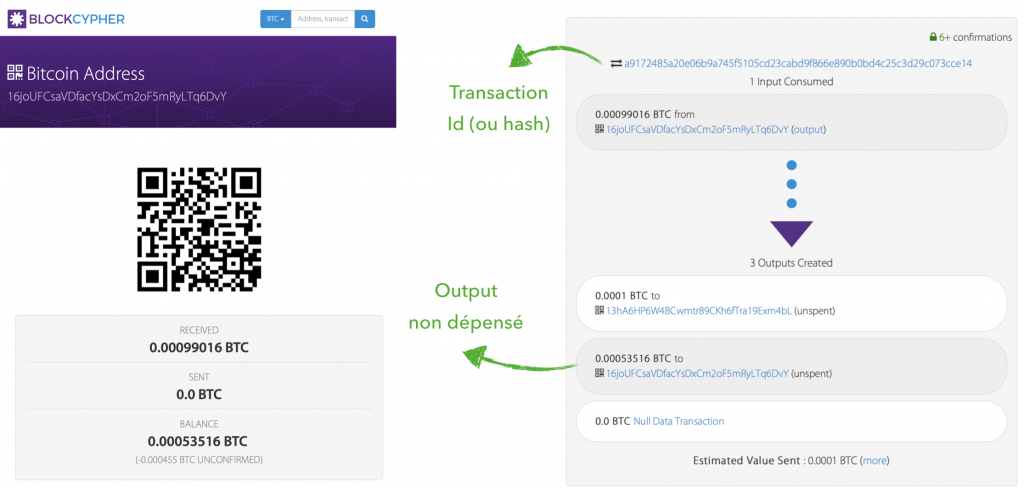
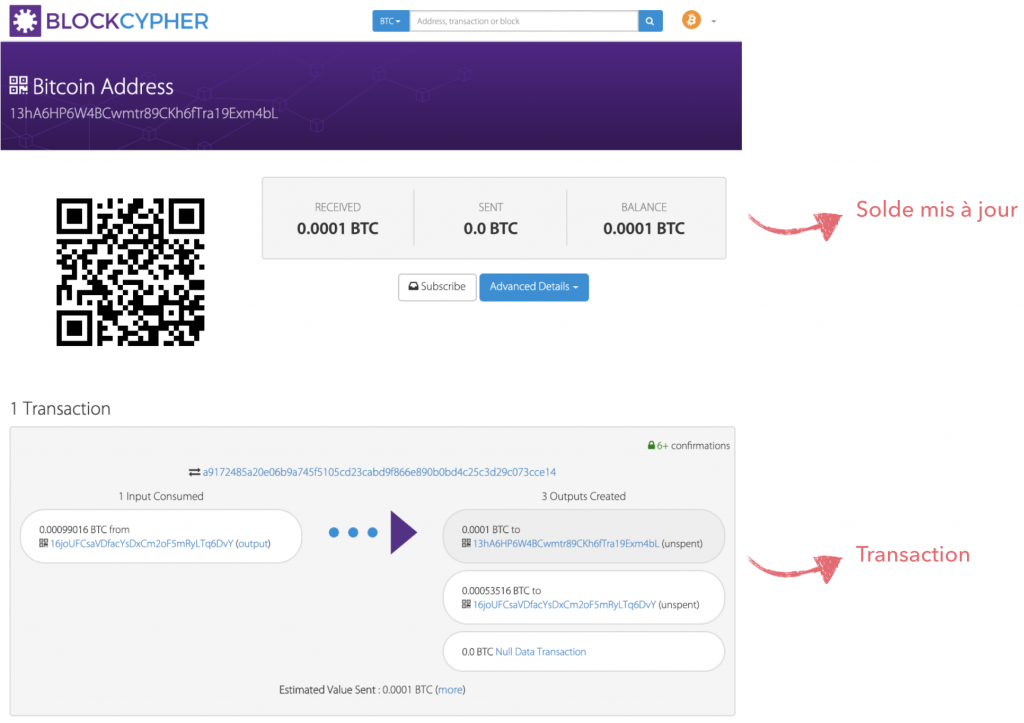
Etape 6 : Consulter les comptes de Bob et d’Alice :
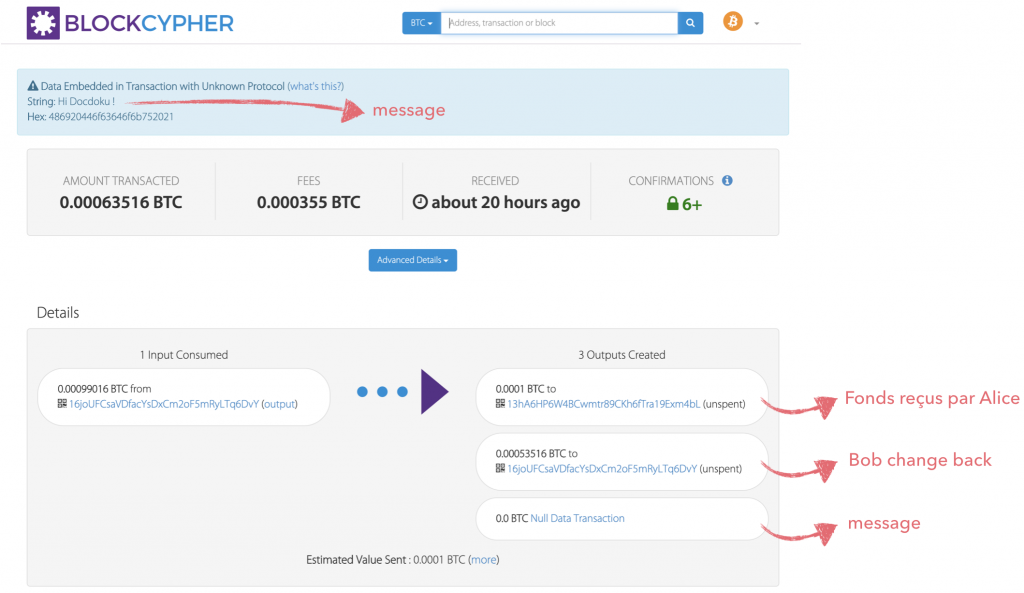
Si on regarde d’un peu plus près les informations fournies par BlockCypher concernant l’adresse de Bob, on peut remarquer deux choses plutôt curieuses au premier abord :
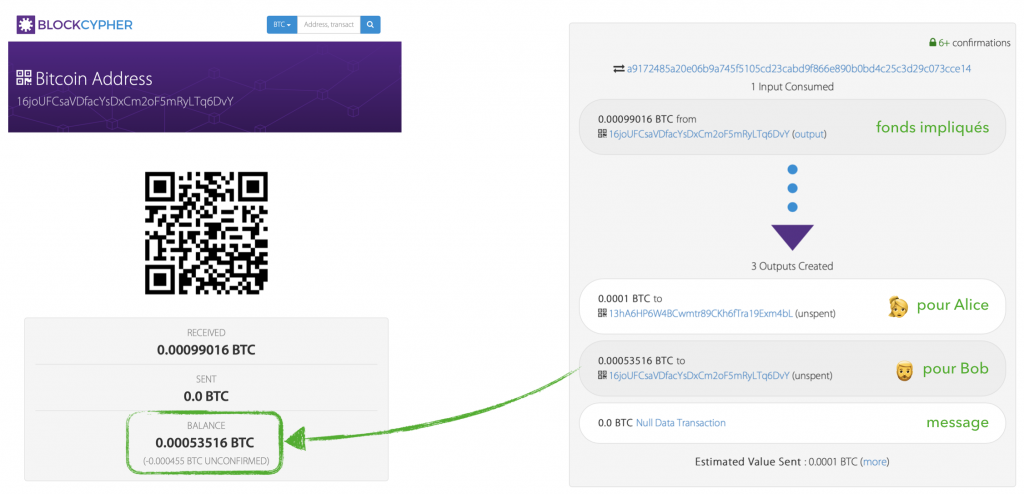
la différence entre le total des inputs et des outputs (0.000355 BTC) → Frais de minage.
Bob se renvoie à lui même une partie des fonds impliqués dans la transaction → Tous les fonds impliqués doivent être dépensés.
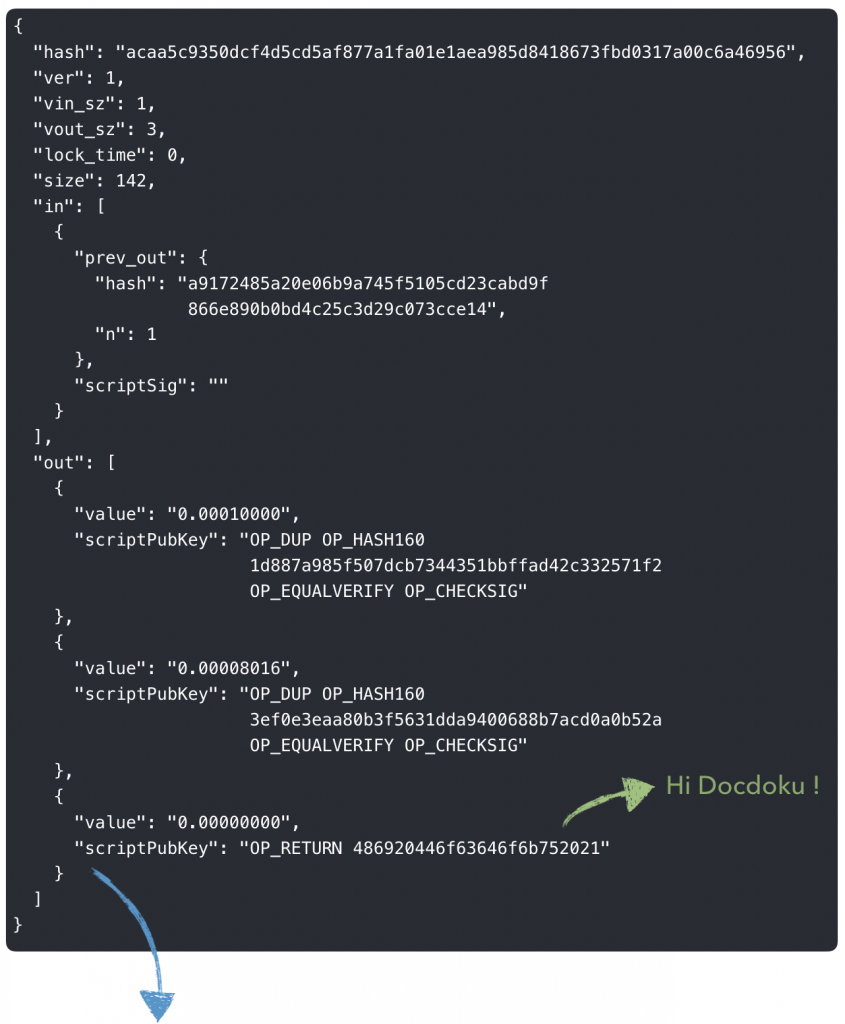
Etape 7 : Analyser une transaction Bitcoin
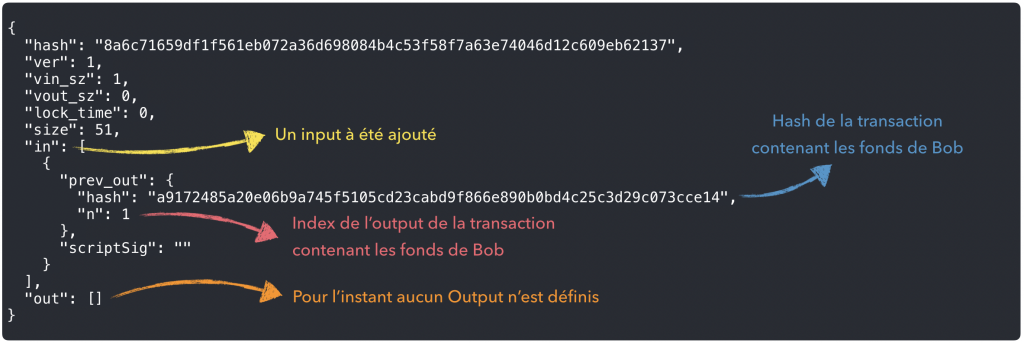
Pour envoyer des fonds de Bob vers Alice, il va donc nous falloir construire une transaction et la soumettre au réseau Bitcoin.
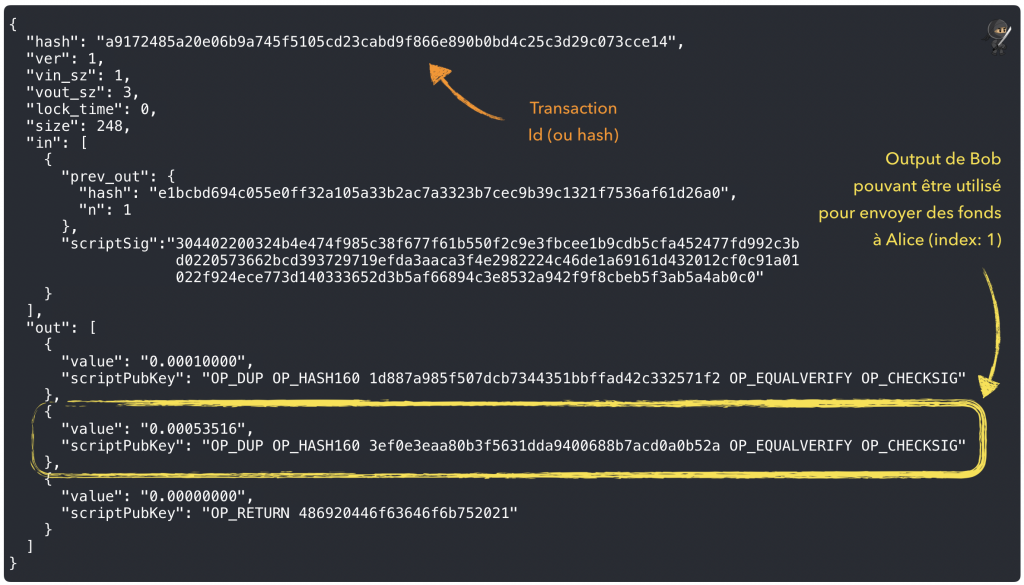
Les transactions sont au coeur du système Bitcoin, elles contiennent les informations relatives aux transferts de valeur entre les participants du réseau.
Pour envoyer des fonds à Alice, il va donc falloir faire référence à l’output d’une transaction qui à transféré des fonds initiaux à Bob et que ce dernier n’à pas dépensé …
En consultant la dernière transaction liées à l’adresse de Bob, on retrouve rapidement cette information :
Notre nouvelle transaction va donc « s’accrocher » à l’output non dépensé de celle-ci !
QBitNinja va nous permettre de récupérer ces informations afin de les manipuler dans notre application console.
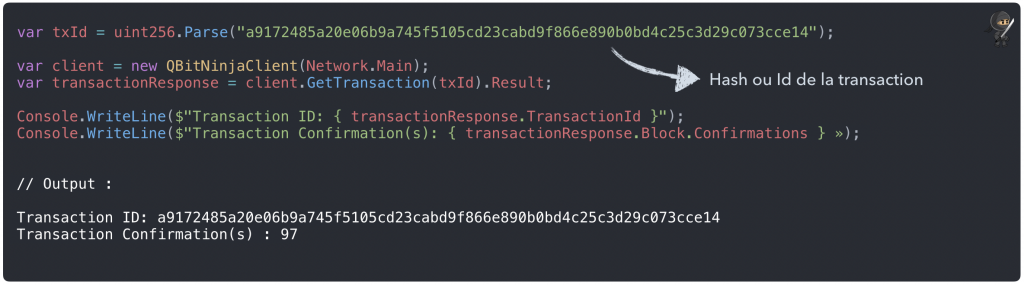
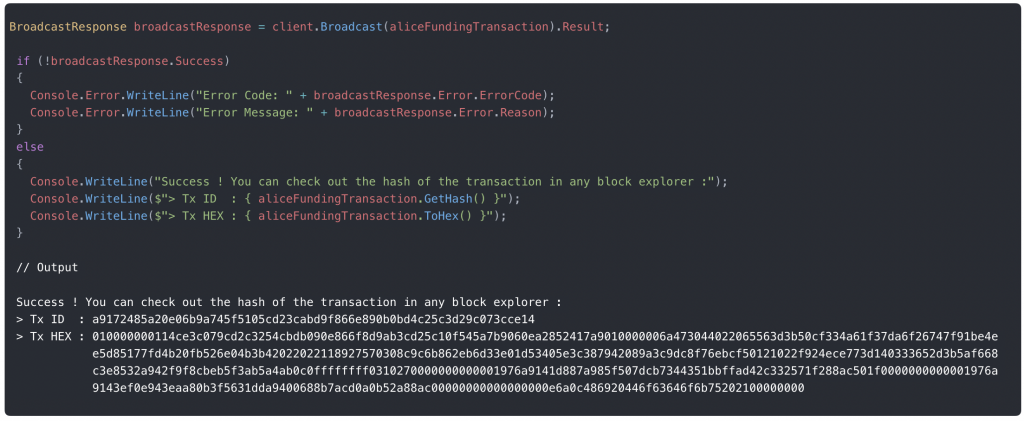
Etape 8 : Récupérer une transaction stockée sur la blockchain avec le client QBitNinja :
Affichons l’intégralité de la transaction :
Résultat :
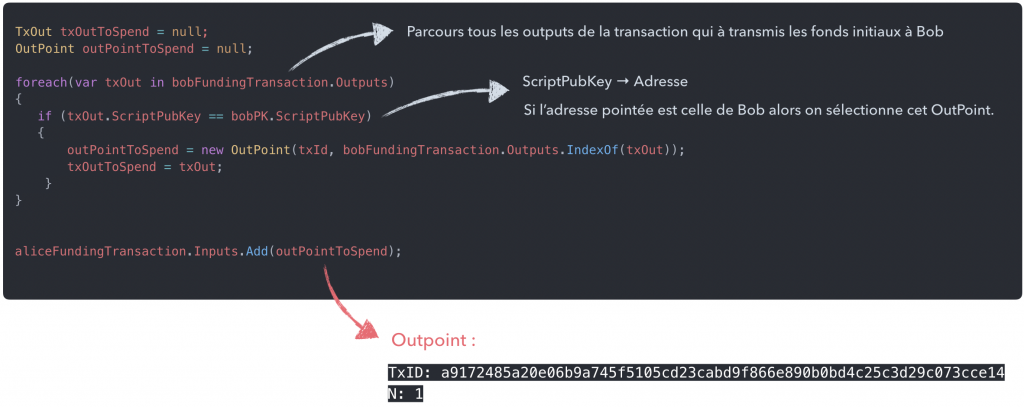
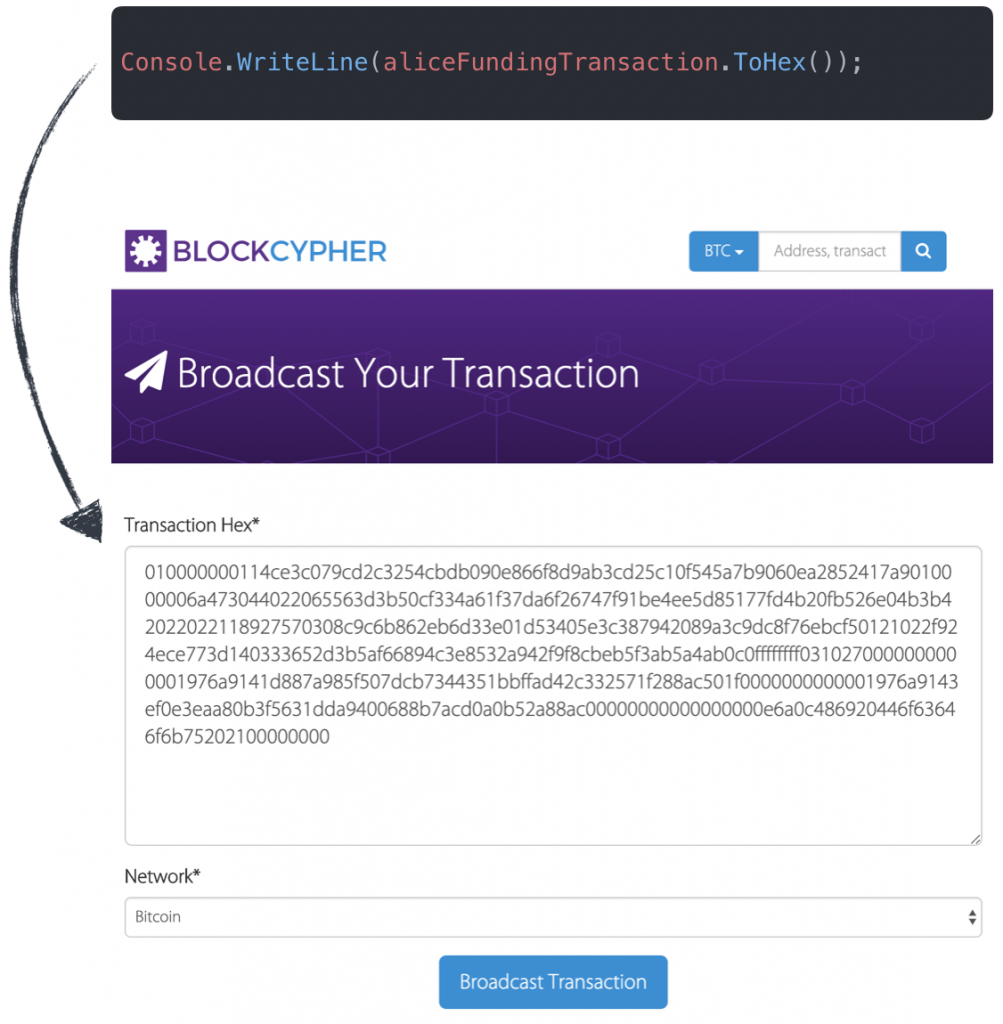
Etape 9 : Construire la transaction Bitcoin
Maintenant que l’ont sait quoi dépenser, on peut commencer à construire notre nouvelle transaction :
Et ajouter un nouvel input à cette nouvelle transaction :
Si on visualise notre transaction à ce stade, on obtient :
Voyons maintenant comment dépenser notre input …
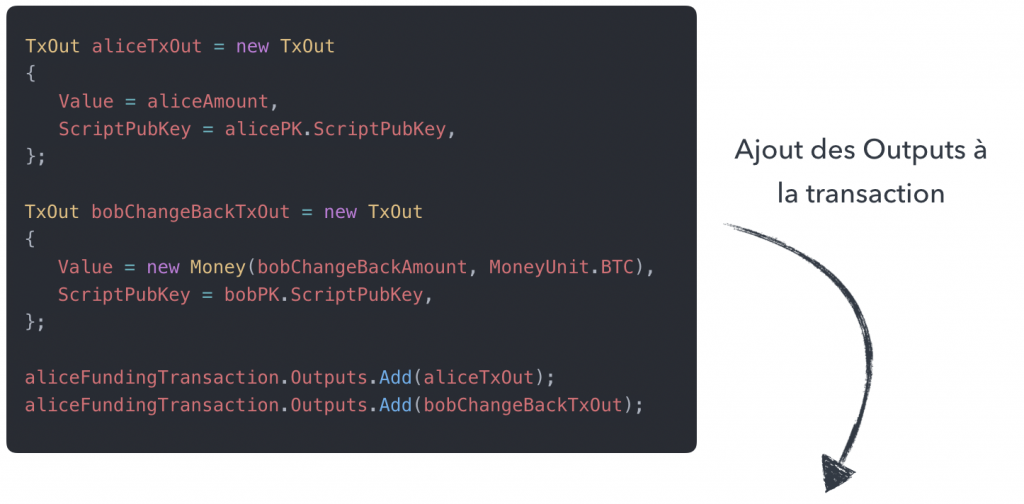
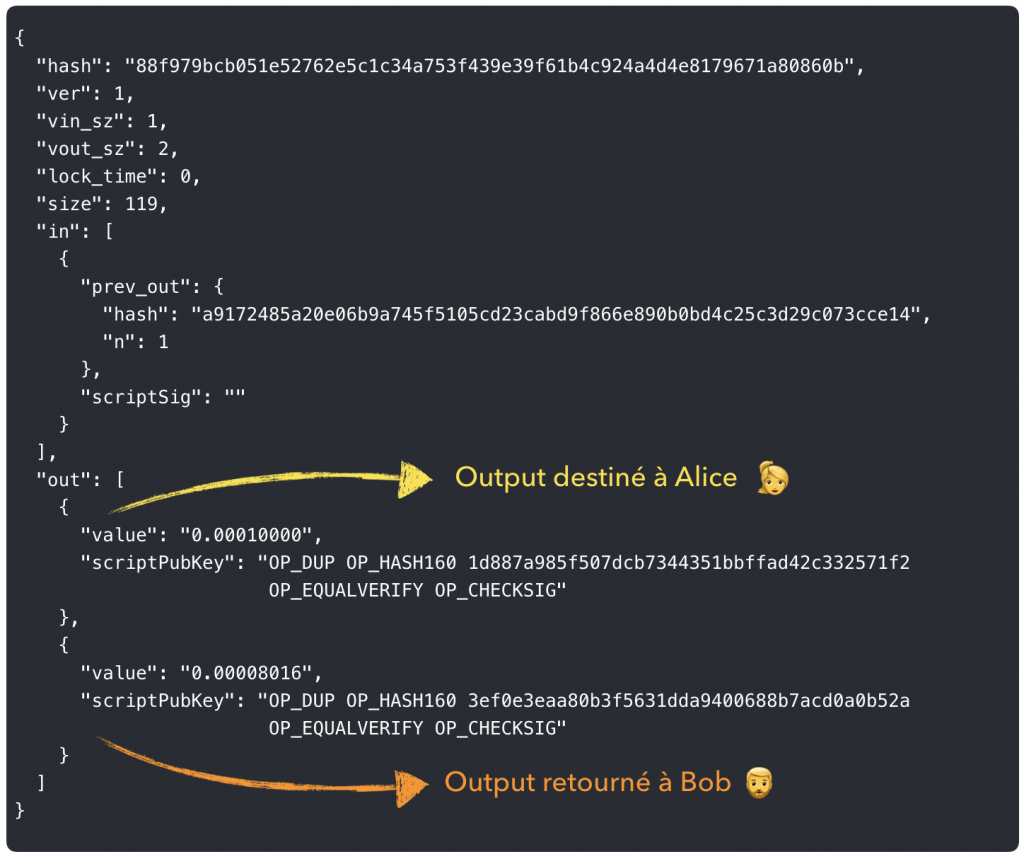
On calcule la répartition des fonds entre les différents Outputs de notre future transaction en respectant le fait que :
tous les fonds en input de la transaction doivent être dépensés,
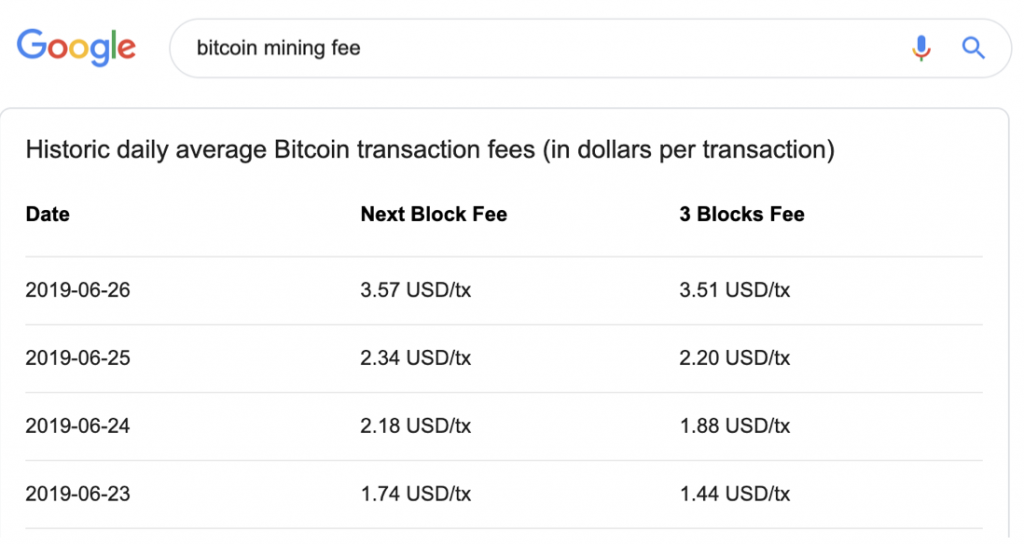
la différence entre le montant total des inputs et des outputs sera reversé au mineur,
des frais de minages trop faibles entrainent un traitement plus long de la transaction (voire elle n’est jamais traitée),
Pour calculer les frais de minages on peut directement chercher sur google :
plus vous payez, plus vite est traitée votre transaction,
il s’agit d’une moyenne, le prix est fixé en fonction du poids de votre transaction.
si vous ajoutez un message, vous devrez augmenter les frais.
L’application première du réseau Bitcoin est l’échange de la cryptomonnaie du même nom.
D’ailleurs sur ce réseau tout se paye en Bitcoins.
Mais il peut également servir à autre chose (et NBitcoin supporte tout cela):
stocker des données de façon indélébile et non-censurable,
émettre et détruire votre propre « tokens » pour représenter les parts d’une entreprise, des actions ou des votes,
attacher un « contrat ricardien » à un token (une sorte de smart contract lisible par l’homme et destiné au monde juridique).
Le protocole est en perpétuelle évolution et vise à devenir de plus en plus efficient (plus rapide, moins coûteux).
Il est également à noter que le coût de transaction n’est pas proportionnel au montant transféré et dépends de la « taille » en bytes de votre transaction. Ainsi, transférer 10$ ou 10M$ aura un coût de transaction équivalent !
Si aujourd’hui la lenteur et les frais de transaction élevés limite l’usage du réseaux, des mises à jour comme le « Lightning Network » ont le potentiel de changer la donne et maintenir Bitcoin sur le devant de la scène.
Avant d’aborder le sujet de la HA (High Availability), il est utile de rappeler quelques principes qui vont être utilisés dans la suite de cet exposé.
RPO et RTO
Il existe plusieurs méthodes de sauvegarde d’une base de données PostgreSQL, chacune présentant des avantages et des inconvénients eu égard à la volumétrie des données, à la granularité des sauvegardes qu’on veut réaliser, à la cohérence des données sauvegardées, au transfert des données entre différentes versions de PostgreSQL et entre machines d’architectures différentes. Par ailleurs, on distingue deux types de sauvegardes : les sauvegardes logiques et les sauvegardes physiques.
Une sauvegarde logique consiste à archiver les commandes sql qui ont servi à générer la base et à les rejouer pour la restauration de celle-ci. Pour celà, il existe 2 commandes dans PostgreSQL : pg_dump et pg_dumpall. On trouvera plus de détails sur ces commandes dans la documentation de PostgreSQL https://www.postgresql.org/docs/10/backup.html.
Une sauvegarde physique ou sauvegarde au niveau du système de fichiers consiste à archiver les répertoires des données de la base en utilisant les commandes de copie ou d’archivage des fichiers du système d’exploitation : tar, cp, scp, rsync, … On peut aussi réaliser une “image gelée” (frozen snapshot) du volume contenant la base de données et ensuite copier entièrement le répertoire de données (pas seulement quelques parties) de l’image sur un périphérique de sauvegarde, puis de libérer l’image gelée.
Les objectifs d’une bonne procédure de sauvegarde sont exprimés par deux métriques :
le RPO (Recovery Point Objective) : représente la quantité maximum de données qu’on peut tolérer de perdre suite à un incident de la base de données.
le RTO (Recovery Time Objective) : représente la durée maximum d’une interruption de service qu’on peut tolérer, le temps de restaurer la base et la remettre en service.
L’objectif idéal étant que ces 2 paramètres soient nuls, PostgreSQL propose des approches qui permettent de s’en approcher. Elles sont basées sur la mise en oeuvre de l’archivage continu et la récupération d’un instantané (PITR : Point In Time Recovery).
Archivage continu et PITR
Cette approche est basée sur l’utilisation des journaux WAL (Write Ahead Log), appelés aussi journaux des transactions. Ils enregistrent chaque modification effectuée sur les fichiers de données des bases. Ils sont stockés dans le sous-répertoire pg_wal/ du répertoire des données du cluster.
La sauvegarde consiste à combiner une sauvegarde de niveau système de fichiers avec la sauvegarde des fichiers WAL.
La restauration consiste à restaurer les fichiers de la base puis de rejouer les fichiers WAL sauvegardés jusqu’à emmener la base à son état actuel.
Avantages :
Il n’est pas nécessaire de disposer d’une sauvegarde des fichiers parfaitement cohérente comme point de départ. Toute incohérence dans la sauvegarde est corrigée par la ré-exécution des journaux
Puisqu’une longue séquence de fichiers WAL peut être assemblée pour être rejouée, une sauvegarde continue est obtenue en continuant simplement à archiver les fichiers WAL. C’est particulièrement intéressant pour les grosses bases de données dont une sauvegarde complète fréquente est difficilement réalisable.
Les entrées WAL ne doivent pas obligatoirement être rejouées intégralement. La ré-exécution peut être stoppée en tout point, tout en garantissant une image cohérente de la base de données telle qu’elle était à ce moment-là. Ainsi, cette technique autorise la récupération d’un instantané (PITR) : il est possible de restaurer l’état de la base de données telle qu’elle était en tout point dans le temps depuis la dernière sauvegarde de base.
Si la série de fichiers WAL est fournie en continu à une autre machine chargée avec le même fichier de sauvegarde de base, on obtient un système « de reprise intermédiaire » : à tout moment, la deuxième machine peut être montée et disposer d’une copie quasi-complète de la base de données.
Contraintes :
approche plus complexe à administrer
ne supporte que la restauration d’un cluster de bases de données complet, pas d’un sous-ensemble
espace d’archivage important requis : si la sauvegarde de base est volumineuse et si le système est très utilisé, ce qui génère un grand volume de WAL à archiver.
La réplication
Dans une architecture maître-esclave, le transfert des données de base et des WAL (Log shipping) peut se configurer de 3 manières légèrement différentes :
Warm Standby : les fichiers des transactions (WAL) archivés sont transférés du maître vers l’esclave par copie et rejoués, avec un retard d’un fichier WAL (16 MB) par rapport au maître. La perte éventuelle de données ne peut donc excéder 16 MB. Dans cette configuration, la base esclave n’est pas accessible.
Hot Standby : le fonctionnement est identique au Warm Standby. La différence est que la base esclave est accessible en lecture seule.
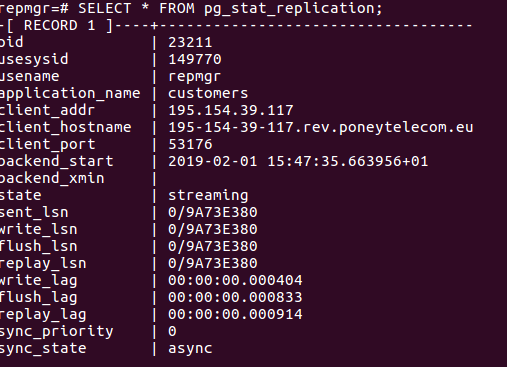
Streaming Replication : dans cette configuration, chaque transaction est transférée vers la machine esclave via le réseau, et rejouée, sans attendre que le fichier WAL soit complété. Ainsi, le RPO est quasiment nul (une transaction perdue au maximum dans une réplication asynchrone, 0 dans une réplication synchrone).
Tolérance à panne
La tolérance à panne (failover) est la capacité d’un système à maintenir un état de fonctionnement en dépit d’une défaillance logicielle ou matérielle. Elle est rendue possible par la réplication. Nous étudierons ici les moyens à mettre en oeuvre pour assurer une continuité de service en toutes circonstances.
Gestion du Failover avec repmgr
Une Architecture Maître/Esclave sert à gérer les situations de failover où la machine Esclave prend le relais en cas de défaillance de la machine Maître.
Pour ce faire, une réplication continue est instaurée entre les 2 machines de telle façon que les données des 2 machines soient quasiment identiques à chaque instant.
Pour pouvoir gérer en plus, la capacité de déclencher la bascule (le failover) automatiquement, il existe plusieurs outils dans l’écosystème PostgreSQL tels que repmgr. Celui-ci peut-être utilisé seul ou en conjonction avec d’autres outils de backup comme BARMAN (Backup and Recovery Manager for PostgreSQL) développé par 2ndQuadrant (https://www.2ndquadrant.com/) avec une licence GPL v3, dont la dernière version est la 2.5 du 23/10/2018 (http://www.pgbarman.org/).
Présentation de repmgr
repmgr est une suite d’outils open source développés par 2dQuadrant ( https://repmgr.org/docs/4.2/index.html) qui mettent en oeuvre la réplication native de PostgreSQL et qui permettent de disposer d’un serveur dédié aux opérations de lecture/écriture (Primary ou Maître) et d’un ou plusieurs serveurs en lecture seule (Standby ou Esclave). Deux principaux outils sont fournis :
repmgr : outil en ligne de commandes pour les tâches d’administration :
configuration des serveurs standby
promotion d’un serveur standby en primary
inverser les rôles des deux serveurs (switchover)
afficher les statuts des serveurs
repmgrd : deamon qui supervise l’état des serveurs et qui permet de :
surveiller les performances
opérer un failover quand il détecte la défaillance du primary en promouvant le standby
émettre des notifications sur des événements qui peuvent survenir sur les serveurs à des outils qui vont déclencher des alertes (mail par exemple)
Architecture
Pré-requis système
Linux/Unix
repmgr 4.x compatible avec PostgreSQL 9.3+
La même version de PostgreSQL sur tous les serveurs du cluster
repmgr doit être installé sur tous les serveurs du cluster, au moins dans la même version majeure*
les connections entre serveurs doivent être ouvertes sur leurs ports respectifs
les accès ssh par échange de clés publiques pour le user postgres de chacun des serveurs doivent être configurés.
Installation
L’installation se fait pour :
RedHat/CentOS/Fedora à partir du repository yum de 2ndQuadrant
Debian/Ubuntu à partir des repository APT de postgreSQL (http://apt.postgresql.org/) ou du repository APT de 2ndQuadrant (https://dl.2ndquadrant.com/default/release/site/)
Les exemples ci-dessous concernent une version 10.x de PostgreSQL
Ajuster les paramètres ci-dessous dans les fichiers de configuration des PostgreSQL (postgresql.conf) :
# Enable replication connections; set this figure to at least one more # than the number of standbys which will connect to this server # (note that repmgr will execute `pg_basebackup` in WAL streaming mode, # which requires two free WAL senders)
max_wal_senders = 10
# Enable replication slots; set this figure to at least one more # than the number of standbys which will connect to this server. # Note that repmgr will only make use of replication slots if # « use_replication_slots » is set to « true » in repmgr.conf
max_replication_slots = 3
# Ensure WAL files contain enough information to enable read-only queries # on the standby. # # PostgreSQL 9.5 and earlier: one of ‘hot_standby’ or ‘logical’ # PostgreSQL 9.6 and later: one of ‘replica’ or ‘logical’ # (‘hot_standby’ will still be accepted as an alias for ‘replica’) # # See: https://www.postgresql.org/docs/current/static/runtime-config-wal.html#GUC-WAL-LEVEL
wal_level = replica
# Enable read-only queries on a standby # (Note: this will be ignored on a primary but we recommend including # it anyway)
hot_standby = on
# Enable WAL file archiving archive_mode = on
# Set archive command to a script or application that will safely store # you WALs in a secure place. /bin/true is an example of a command that # ignores archiving. Use something more sensible. archive_command = ‘/bin/true’
Création du user repmgr et du schéma repmgr
Le schéma repmgr sert à enregistrer les données de monitoring de repmgr. On y accède avec le user repmgr. Ils doivent être créés sur chacun des instances des serveurs :
sudo -i -u postgres
psql -p 5432
create role repmgr with password ‘password123’ ; alter role repmgr login ; alter role repmgr replication ; alter role repmgr superuser;
CREATE DATABASE repmgr OWNER repmgr;
Configuration de pg_hba.conf
L’objectif de cette configuration est de permettre au user repmgr de se connecter en mode replication :
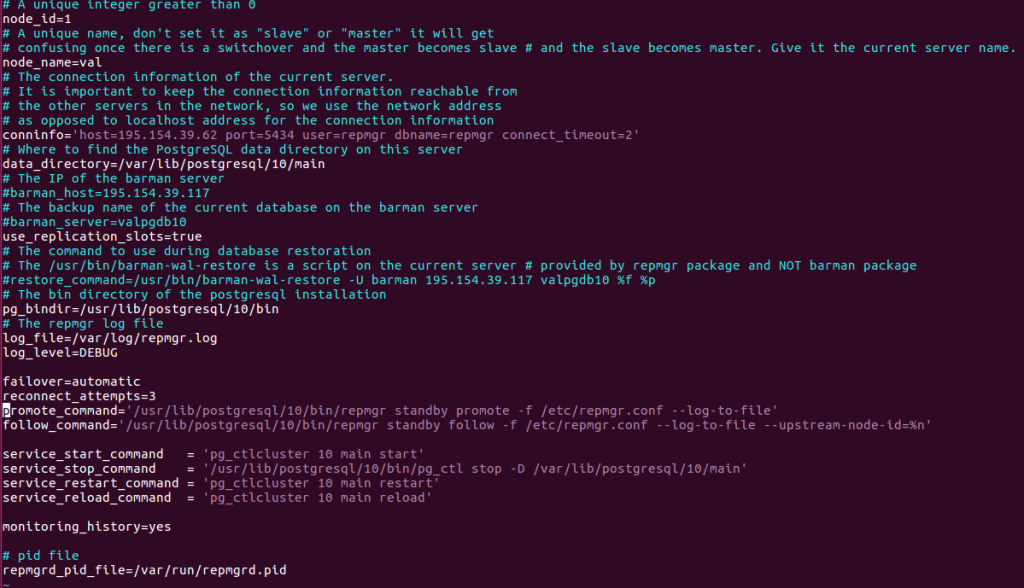
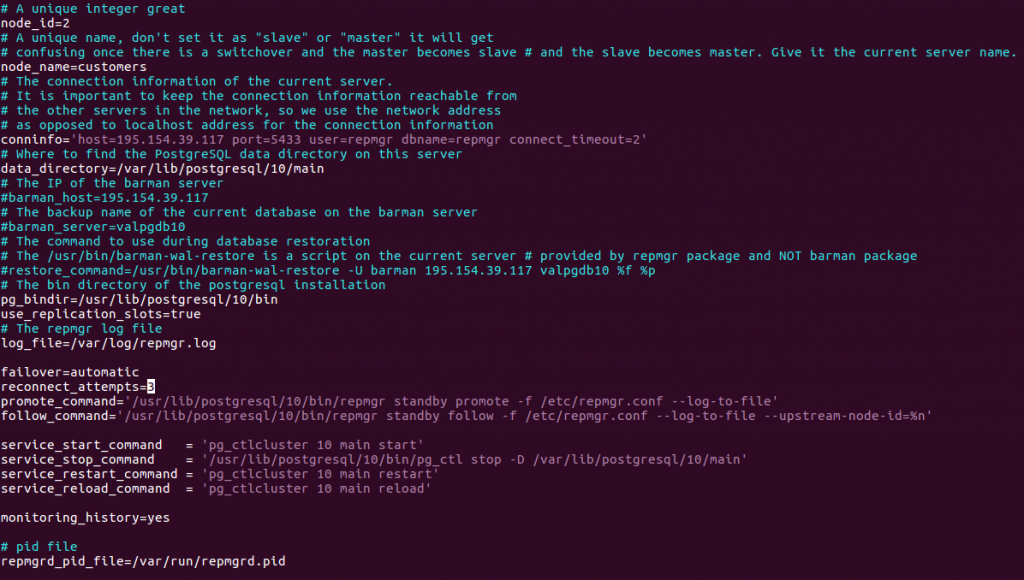
La configuration se fait dans le fichier /etc/repmgr.conf aux niveau du primaire (node_id=1, node_name=val) et du standby ((node_id=2, node_name=customers).
Remarques :
Les paramètres indiqués ci-dessus sont les paramètres de base pour un fonctionnement standard de repmgr. On trouvera d’autres paramètres disponibles dans le fichier repmgr.conf.sample fourni dans la distribution.
Enregistrement du serveur primaire
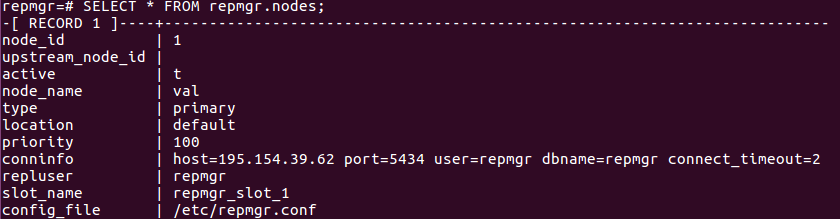
L’enregistrement du serveur primaire auprès de repmgr va créer les métadata dans le schéma repmgr et y initialisera un enregistrement correspondant au serveur primaire :
Avec le user postgres , exécuter la commande suivante :
$ repmgr -f /etc/repmgr.conf primary register
Vérifier le statut du cluster avec la commande suivante :
Les metatda sont affichés avec la commande suivante :
Configuration du serveur standby
Créer le fichier de configuration /etc/repmgr.conf, similaire à celui du primaire. Il diffère essentiellement par le n° et le nom du noeud ainsi que la chaîne de connexion conninfo :
Clonage du serveur standby
On exécutera la commande de clonage en dry-run pour s’assurer que toutes les conditions de succès sont satisfaites :
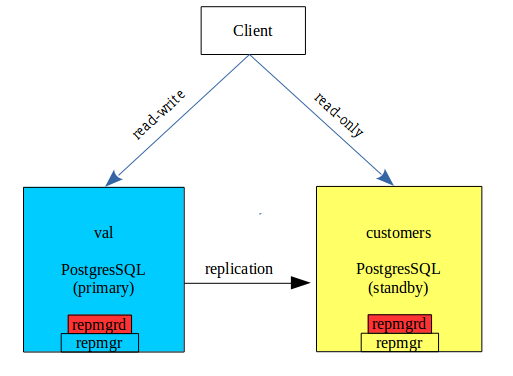
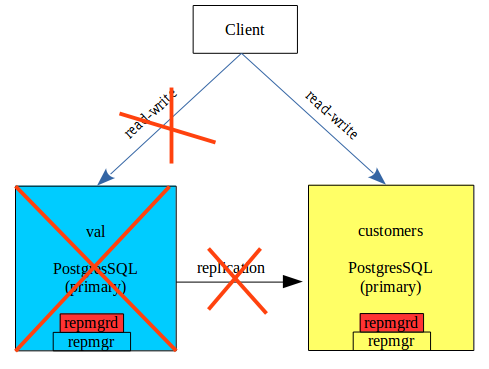
Dans le schéma ci-dessus, si val est indisponible , customers est promu en primary, et en mode read-write. Ce failover peut être exécuté manuellement avec 2 commandes de repmgr :
Au niveau de customers : /usr/bin/repmgr standby promote -f /etc/repmgr.conf –log-to-file
Au cas où il y aurait plusieurs serveurs standby, on exécute au niveau de chacun une commande de follow, qui leur indique le nouveau serveur maître :
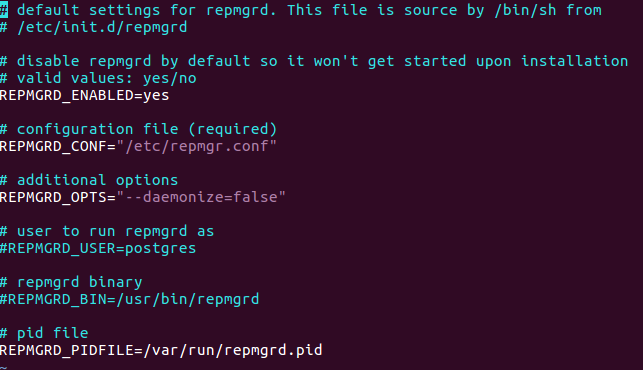
Si repmgr a été installé à partir des packages de Debian/Ubuntu, il faudra configurer pour que repmgrd tourne en daemon, via le fichier /etc/default/repmgrd , dont le contenu est le suivant :
Démarrage de repmgrd
Pour démarrer repmgrd, exécuter la commande suivante sur chacun des serveurs, en tant que postgres :
Une fois, val “réparé”, le retour à la situation initiale s’effectue en 2 temps : d’abord mettre val comme standby du primaire customers puis faire un switchover sur val pour qu’il redevienne primaire et customers redevient standby :
Cloner val à partir de customers et l’enregistrer comme standby :
On constate que le cluster fonctionne avec customers comme primaire et val comme standby.
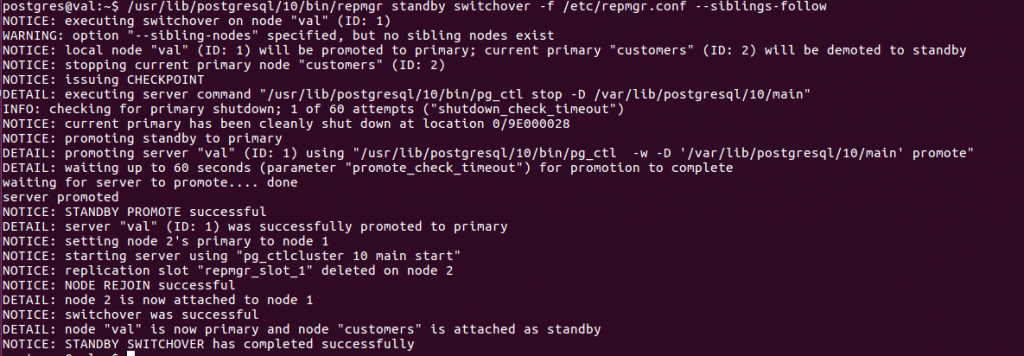
Pour inverser les rôles, on fait un switchover sur le standby :
Vérifier l’état du cluster
Remarque : le switchover agit sur le standby et sur les autres serveurs pour qu’ils soient avertis du nouveau primaire.
Conclusion
Ce post a permis d’exposer pas à pas les étapes pour configurer une HA sur un cluster à 2 noeuds, en mode primaire/standby. Pour ce faire, on a mis en oeuvre une streaming réplication avec repmgr et un monitoring des 2 noeuds avec le daemon associé à repmgr, ce qui permet de déclencher le failover automatique en cas de défaillance du noeud primaire. Le retour à la configuration initiale, après réparation de la défaillance, est réalisé avec un switchover. Le protocole de streamaing réplication permet de minimiser le RPO car il permet de rejouer les transactions au fil de l’eau au niveau du standby. Pour minimiser le RTO, il faut ajuster la fréquence des backup de base en fonction de la volumétrie des transactions.
La configuration qui a été présentée ici, peut être renforcée par un système de load balancing par un outil tiers dans le cas général , style pgpool-II ( http://www.pgpool.net ) ou par le driver jdbc si on est dans l’écosystème java.
By Mathilde Salthun-Lassalle/13 janvier 2019/3 Commentaires
* La désignation ne fait pas consensus et la liste des termes synonymes est très longue : Feature Flag, Feature Switch, Conditional Feature, Feature flipper, Feature Bits, Gatekeepers….
Le principe
À la livraison d’une nouvelle version d’un logiciel sur un environnement, toutes les nouvelles fonctionnalités sont rendues disponibles immédiatement. Au contraire, le modèle de design Feature Toggle* a pour but de fournir un interrupteur de fonctionnalités qui active ou désactive une partie du code sans nécessiter ni redéploiement ni redémarrage de l’application.
Les usages possibles
Cette fonctionnalité peut avoir de nombreux usages. Les cas suivants en sont un exemple et ne représentent pas l’exhaustivité des situations.
CAS 1 – Différents besoins sur différents environnements
Pratiquer des livraisons régulières, fréquentes et de petite taille est une des conditions à garantir pour l’agilité d’un projet (Continuous Delivery). L’enjeu est le maintien d’un cycle de développement court pour limiter les risques du rythme élevé de changements. Or si cette stratégie s’avère un atout en environnement de recette, où la validation de petites briques logicielles réduit la durée de la phase de tests, elle peut être difficile à réaliser en environnement de production. En effet, une fonctionnalité peut représenter plusieurs itérations de développements et il serait incongru de la mettre à disposition de l’utilisateur de façon incomplète. Le système de feature toggles rend possible la livraison de parties de fonctionnalités en mode désactivé sans que cela n’affecte la stabilité du code. L’activation pourra être réalisée au bout de quelques semaines, une fois que l’ensemble du code nécessaire aura été livré.
CAS 2 – Incident suite à une livraison
Lorsqu’un dysfonctionnement est rencontré en production par un utilisateur suite à une récente livraison, il sera possible de désactiver la fonctionnalité pour réduire l’instabilité du logiciel en attendant une résolution.
CAS 3 – Dépendances entre équipes
Il n’est pas rare que plusieurs équipes travaillent en parallèle sur des besoins différents et dans des délais qui leur sont propres tout en ayant en commun une ou plusieurs applications. Par exemple, l’interface peut être la même pour toutes les équipes. Lorsque le moment est venu pour une équipe de livrer son travail, elle se trouve gênée par les développements encore en cours ou en validation des autres équipes sur l’application partagée. Si chaque équipe a mis en place des toggles, la livraison sera envisageable à la condition que chaque fonctionnalité non encore terminée soit désactivée.
CAS 4 – Tests comparatifs
Il existe une catégorie de Feature toggles dont l’activation se fait par utilisateur. La condition d’activation peut être déterminée par un profil de permissions ou encore l’appartenance à un échantillon. Au lieu de plusieurs environnements, un seul est nécessaire pour comparer des résultats entre différents groupe d’utilisateurs et valider une approche.
AUTRES CAS – L’activation de fonctionnalités peut aussi…
concerner la configuration d’un système opérationnel déjà en service afin de déterminer les meilleurs paramètres (court terme) ou bien de maintenir un service stratégique au détriment d’un autre en dégradant les performances à son profit (long terme)
être amenée à rester sur le long terme dans le cas du besoin de customisation de fonctionnalités par utilisateur (par exemple un mode « utilisateur premium»)
Selon Martin Fowler 1 – son blog, il existe deux axes de qualification pour un feature toggle, son dynamisme (changements au déploiement / à chaud / par requête) et sa longévité (nombre de jours / mois / années). Cette classification doit orienter vers le choix d’une implémentation.
Un rapide aperçu avec FF4J
FF4J (Feature Flipping for Java) est un framework en licence libre apache 2.
Une fois les dépendances nécessaires ajoutées (ff4j-core, junit, ff4j-web) et la configuration paramétrée, il faudra créer un service fournissant une instance de la classe FF4J.
Étape 1. Créer un feature toggle
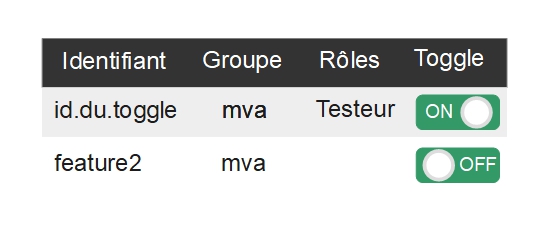
Cela consiste à insérer une nouvelle entrée dans un feature store (le système de stockage) précisant l’identifiant du toggle, sa description, son statut d’activation, son groupe d’appartenance, les rôles d’utilisateurs ou les stratégies associés. L’offre de système de stockage des données est large : mémoire, bases relationnelles ou no-sql.
ci-dessus : Table prévue pour le stockage en base relationnelle, le champ « enable » stocke 1 pour le statut « activé » 0 pour « désactivé ».
Étape 2. Utiliser le feature toggle dans le code
L’identifiant choisi à l’étape 1 permettra de vérifier l’état d’activation.
If (ff4j.check("id.du.toggle")) {
doBehiavorA()
} else {
doBehiavorB()
}
ci-dessus : si le toggle est activé alors le comportement A est joué sinon le comportement B fonctionne.
Étape 3 . Déployer le code sur un environnement
Étape 4 . Contrôler l’activation via la console d’administration
ci -dessus : Une interface graphique permet de réaliser l’opération sans nécessiter de compétences techniques.
Limites
Ce mécanisme complexifie le code : deux cas de comportements sont implémentés en même temps donc deux fois plus de code. Il est donc conseillé de réfléchir aux bons emplacements stratégiques dans le code et de limiter le nombre de recours. Dans le même ordre d’idée, le nombre total de fonctionnalités couvertes se doit de rester faible pour rester maintenable. Heureusement, ce risque est diminué dans la plupart des usages puisqu’ils répondent à un besoin temporaire. Néanmoins, cette situation temporaire va induire une opération supplémentaire de nettoyage du code, une fois que la fonctionnalité est activée de manière définitive. Il existe également quelques cas où la sécurisation avec un toggle n’est pas envisageable. J’ai notamment déjà rencontré le cas lors d’un changement structurel important au niveau du modèle en projet . Il existe une controverse. En effet, les outils de gestion de versions (tel que Git) apportent une aide précieuse dans la résolution de certaines problématiques (ex. CAS 3). Si la pratique très courante du Feature Branching (séparation des fonctionnalités en branches) est jugée inadaptée face au défi de l’intégration et de la livraison continues pour les uns 1 – martin fowler blog, elle reste une réponse possible lorsque bien exécutée pour d’autres 2 – james mckay blog. Ces approches peuvent aussi être utilisées côte à côte.
Enfin, cette approche va de pair et prendra tout son sens dans un contexte où l’automatisation des tests et des déploiements est déjà en place.
Les 13 et 14 juin prochains, DocDoku vous donne rendez-vous dans la ville rose pour l’EclipseCon France 2018, le grand rassemblement annuel français de la communauté Eclipse.
Comme lors de la précédente édition, DocDoku reste fidèle à son engagement en tant que sponsor de l’événement et vous accueillera sur son stand pour parler solutions et technologies, mais également présenter ses derniers cas clients.
Le programme de la conférence 2018 couvrira cette année des sujets en lien avec la modélisation, les systèmes embarqués, le Cloud, la Data Analytics, le DevOps et plus encore, le tout agrémenté de sessions de démonstration des outils basés sur Eclipse.
Cette année nous serons particulièrement attentifs aux conférences sur l’arrivée dans la fondation du groupe de travail JakartaEE, auquel DocDoku appartient désormais.
En effet, ce projet ambitieux prend la suite de la renommée plateforme de développement d’applications d’entreprise Java Enterprise Edition, maintenue par Oracle précédemment.
Nous resterons également captivés par les conférences du groupe de travail Polarsys, auquel DocDoku participe également au travers de la plateforme PLM d’Eclipse EPLMP.
« Aucune de mes inventions n’est arrivée par accident. J’ai entrevu un besoin qui méritait d’être comblé et j’ai fait essai après essai jusqu’à ce que cela vienne ». Thomas Edison
Pour commencer, comment définir la méthodologie Agile dans le développement de projets logiciels ?
De façon simple, l’Agilité invite à exécuter en parallèle les activités suivantes :
gestion des exigences (expression des besoins du Client),
analyse et conception,
codage et test,
suivi du projet.
Quelle est la vision de DocDoku au regard de l’Agilité ?
Bien avant la création de DocDoku en 2006, ses fondateurs, Eric Descargues et Florent Garin, appliquaient déjà cette méthodologie dans les projets qui leur étaient confiés. Inscrite dans l’ADN de la société, l’Agilité fait donc naturellement partie des projets développés par DocDoku, qu’il s’agisse de Data Management ou du développement d’applications digitales métier.
Et concrètement comment l’engagement dans les méthodologies Agile se traduit-il ?
Tout projet est organisé en « realeases ». Chaque release se décompose en plusieurs itérations à la fin desquelles un incrément du projet est livré au client.
Cette organisation permet de proposer au client le plus tôt possible une version visible de son projet pour qu’il puisse se projeter et faire au besoin les ajustements nécessaires. Le principe est d’éviter l’effet « tunnel », incompatible avec l’atteinte des objectifs (coûts, qualité, délai) du projet.
Enfin, chaque itération est soumise au « time-boxing », c’est à dire qu’elle est limitée dans le temps (de 2 à 4 semaines) pour assurer un excellent respect du planning.
Données Métier : quelles bonnes pratiques pour renforcer la sécurité ?
Faire le choix d’une plateforme de Data Management est une étape importante pour toute entreprise souhaitant piloter de façon innovante sa stratégie ou trouver de nouveaux relais de croissance. Son usage sur tout type de terminaux pose la question de la sécurisation du système, et par extension de la sécurisation des données de l’entreprise vis à vis de l’extérieur.
Le choix d’une plateforme est également une opportunité pour renforcer la sécurité de vos données Métier.
Bien choisir sa plateforme de Data Management
Notre conseil est de privilégier une solution éprouvée, en veillant en particulier à ce que :
La plateforme autorise, si nécessaire, le chiffrement des données stockées
Les mécanismes d’authentification reposent sur des standards modernes (token JWT, OpenID Connect…)
Les communications soient effectuées aux travers de protocoles sécurisés (HTTPS…)
Pour conclure, la maintenance sera également une composante clé de toute démarche visant à créer ou à renforcer la sécurisation des données . Il est important de s’assurer d’être accompagné par des partenaires internes ou externes disposant d’une expertise technique éprouvée et constamment actualisée.
Dans l’IoT, les standards se mettent peu à peu à intégrer les problématiques de sécurité mais ce mouvement est cependant encore trop peu avancé. Le potentiel de calcul sur les données collectées peut être détourné pour un usage malveillant.
Dans ce contexte, quelle solution pour sécuriser ?
L’idée est d’abord de sortir de l’approche périmétrique en sécurisant la passerelle, et permettre ainsi la supervision des communications entre les objets.
De plus, au niveau de la plateforme de gestion des données IoT choisies, si bien sûr plusieurs critères doivent être évalués, il y en est un de crucial : la capacité de celle-ci à gérer l’identité des dispositifs et individus s’y connectant.
Pour aller plus loin…
10 bonnes pratiques pour sécuriser l’IoT dans votre entreprise expliquées ici
Comprenez vos points de terminaison
Suivez et gérez vos appareils
Identifiez ce que la sécurité informatique ne peut pas traiter
Envisagez l’application de correctifs et de résolutions
Utilisez une stratégie pilotée par le risque
Procédez à des tests et des évaluations
Changez les références d’identité et les mots de passe par défaut
Observez les données
Appuyez-vous sur des protocoles de chiffrage à jour
Passez du contrôle au niveau des appareils au contrôle au niveau des identités
En novembre dernier, le salon Mobility for Business réunissait plus de 3 000 décideurs sur les perspectives et les enjeux de la Mobilité aujourd’hui. La sécurité des données a été un des principaux fils rouges des conférences, preuve que le sujet est plus que jamais d’actualité pour les entreprises.
Mobilité et sécurité riment-elles toujours ?
La question se pose. Le premier contre-exemple a retenir est celui du protocole WPA2 – niveau de sécurisation le plus élevé du Wifi – qui a révélé plusieurs failles de sécurité majeures en octobre dernier. Ces failles compromettent la sécurité des réseaux personnels (box FAI par exemple) et professionnels : la récupération malveillante de données personnelles semblait alors possible.
A partir de ce constat, comment construire un réseau fiable ?
En prenant conscience que nous sommes entrés dans une nouvelle ère. De nouveaux outils deviennent indispensables pour sécuriser les comportements mobile et sortir des modèles de sécurisation utilisés pour le PC. Pour la détection du risque mobile, la logique de signature devient obsolète et doit être remplacée par une approche Machine Learning / Big Data avec l’usage de systèmes auto-apprenant de surveillance du réseau.
Technique mais pas que
L’évolution des besoins et usages des utilisateurs doit être pris en compte par la DSI. Intégrer un Proof Of Concept pour tester les moyens d’assurer la sécurité est une bonne démarche. L’enjeux est de trouver le compromis entre un bon niveau de sécurité et une expérience Utilisateur qui reste la plus fluide possible.
Le enjeux sont donc techniques mais ne doivent pas oublier l’Humain : coordonner les comportements et faire de chacun un ambassadeur de la sécurité des données de l’entreprise.
1 pile AAA : c’est l’unique source d’énergie requise pour alimenter pendant 13 ans un dispositif IoT qui générerait un message toutes les heures. Pour relayer l’information, un réseau LPWA (Low-Power Wide-Area) peut être mis en place.De longue portée même en zone très dense, ce réseau permet de transmettre des données au travers d’une configuration en étoile. Il est simple à déployer avec un nombre de stations radio réduit, consomme peu et ses coûts de souscription sont faibles. Cela vous donne peut-être des idées pour vous développer dans l’IoT ?
Quelques points clés à retenir avant de vous lancer.
Trouver le lien entre objet et usage
Se lancer dans l’IoT, c’est rechercher de nouvelles sources de valeur dans la résolution de problèmes « basiques » ou dans des usages inédits, comme par exemple :
La bouche à incendie connectée : l’objet alerte la plateforme en cas de fuite. Il est ensuite possible de couper en direct l’arrivée d’eau depuis la plateforme
Le compteur d’eau connecté : pour alerter lorsqu’aucune consommation n’est relevée pendant une période donnée dans le cadre de la surveillance de personnes âgées restées à domicile ; dans l’hôtellerie pour vérifier le « point mort » quotidien (son absence démontre la présence d’une fuite)
Intégrer le bon support pour gérer vos données IoT
Piloter les objets (marche/arrêt, surveillance batterie, gestion des messages) et de provisionner les objets
Collecter les données produites par l’objet
Analyser les données
En effet, l’objet connecté en lui-même ou le réseau n’a aucune valeur : c’est bien la data produite qui en a.
Créer de la valeur pour votre business
L’IoT vous permettra d’enrichir votre offre ou de passer à la « next generation » de vos produits.
Une chaudière connectée permet aujourd’hui à son constructeur de créer une relation digitale avec son client final. Il peut assurer une maintenance en direct et donner des conseils personnalisés, en fonction de l’usage de son client.
De nouveaux services voient le jour. Avec l’amélioration de la précision des capteurs, il devient aujourd’hui possible de communiquer au client que sa livraison est à « X minutes de chez lui ».
Alors, quels usages avez-vous décidé de développer ?
Source : article rédigé suite à notre participation à Cloud Expo Paris.
1 à 2 ans : c’est la vitesse de renouvellement des technologies informatiques actuelles. Qui permettent entre autres de produire et de traiter toutes vos data. Utiliser les technologies, c’est aussi s’assurer un avantage concurrentiel, un pouvoir d’action et d’adaptation face à l’accélération des marchés.
La vitesse de transformation de l’Entreprise se fait sous un rythme moins soutenu, entre 5 à 7 ans.
Dès lors, comment construire un pilotage de qualité, centré sur les données ?
Retrouvez 6 clés pour vous orienter dans cette démarche.
1. Rester concentré sur vos objectifs business
L’Intelligence Artificielle est-elle indispensable alors que je ne suis pas encore capable de faire une segmentation sur ma base client ?
Il faut décliner la transformation de votre métier en plusieurs étapes, pour que l’organisation ait le temps de s’adapter. Pour vous accompagner et prendre du recul, vous pouvez faire appel à des méthodologies éprouvées comme l’approche OKR (Objectives and Key Results, utilisée chez Google et Uber) ou encore l’approche Agile. La clé est de poser les jalons de votre transformation et de prendre le temps de vous projeter dans ce changement.
2. Ne pas se laisser distraire
Data mining, Data Science ou encore Machine Learning : nombreux sont les nouveaux termes liés de près ou de loin à la gestion des données. Ils rejoindront vos plans stratégiques ou vos communications en temps utile. Pour le moment, il s’agit d’évangéliser les équipes sur la transformation, de se faire comprendre et non de complexifier.
La priorité est de définir la finalité du projet de transformation et son application concrète, avant même de lier les activités de l’Entreprise à de nouvelles terminologies.
3. Penser une gestion fédérée des données
La mise en place de la directive GDPR implique une organisation centralisée. Une instance de gouvernance des données devient indispensable : elle a a pour but d’optimiser la rationalisation des données et surtout de considérer la data comme une sujet transverse (RH, Finance, Process..).
La mise en place de cette approche vous permettra en outre de faire le point sur votre organisation (le système actuel produit-il beaucoup de doublons par exemple ?) et le partage des données.
4. Etablir une gouvernance des données
L’objectif est que la data soit diffusée et maitrisée partout.
Même si vous n’êtes pas prêt à investir massivement, il est important de mettre en place une « Roadmap Data » qui intègre dans tout projet le budget et les ressources à mobiliser pour faire avancer la Data.
5. Se concentrer sur la qualité des données avant tout
Depuis 10 ans, un problème récurrent subsiste malgré les évolutions technologiques : la qualité des données.
Même si l’ERP, le Data Marketing ou encore le Sql ont tenté d’apporter de la structure et d’optimiser la qualité, la présence de données de moins en moins structurées n’a pas joué en faveur de leur qualité.
Un bon modèle sans bonnes données, c’est un simple algorithme.
A vous de jouer…
6. S’ouvrir à l’extérieur
Le développement de l’entreprise étendue a eu pour conséquence d’ouvrir vers l’extérieur l’intégration et l’exploitation des données. La GDPR est une opportunité à saisir mais elle oblige à raisonner en « Privacy by design », c’est à dire à intégrer la protection des données dès leur conception et à anticiper leurs usages et leurs limites.
Cette évolution incite l’Entreprise à s’appuyer sur ses ressources externes et à créer un business modèle basé sur l’interopérabilité.
Il s’agit également de considérer la donnée sous l’angle éthique ou « bien commun » et de développer la transparence.
En conclusion, quelques pistes de réflexion basées sur des exemples d’usage.
La Française des Jeux propose au téléchargement l’ensemble des grilles de résultats du loto. Pouvez-vous partager certaines de vos données pour renforcer votre image de transparence, voir créer de nouveaux relais de croissance ?
Dans ses projets liés à la lutte contre la fraude et le blanchiment, la FDJ intègre un référent Marketing et un Data Steward (administrateur des données internes) pour que tout projet puisse être co-construit dans une logique d’ouverture. Pourquoi ne pas intégrer un nouveau profil à vos équipes projets, comme un Change Manager pour accompagner au quotidien l’évolution de votre organisation, vérifier l’intégration du changement dans les projets, évangéliser et communiquer sur les nouveaux usages ?
Cet article a été rédigé suite à notre participation à Cloud Expo 2017 et à la conférence de Mathias Oelher Chief Data Officer à la Française des jeux.
Depuis plus d’une dizaine d’années, l’évolution des architectures logicielles a pris le virage du web. Cette transformation n’a pas été simple pour les entreprises. Ses détracteurs relevaient des failles de sécurité ou des problèmes de disponibilité. Ils se sont néanmoins laissés convaincre peu à peu par les apports incontestables des systèmes web tant en terme d’ergonomie – gage d’un engagement accru des utilisateurs – que de scalabilité.
Cette dernière permet en effet d’ouvrir un potentiel quasi-illimité pour répondre aux enjeux de production de données, liées à la transformation digitale des entreprises et de leurs modèles de développement au global.
Traduire la réflexion stratégique en solutions informatiques concrètes
L’engagement de DocDoku sur des projets d’accompagnement à l’évolution technologique est visible à chaque étape de la transformation de l’entreprise.
DocDoku a ainsi accompagné dernièrement la réflexion stratégique de l’informatique de la MSA, le GIE AGORA.
Le projet entendait expérimenter la faisabilité technique de la ré-écriture d’un outil de gestion avec la technologie ELECTRON. Pour rappel, ce framework a été la source du développement de nombreuses applications basées sur des technologies web comme WordPress ou Slack.
Nicolas Cazottes, manager équipe Socles Techniques au sein du GIE AGORA, exprime son ressenti à l’issue du projet : « DocDoku a atteint l’objectif que nous avions fixé, à savoir la réalisation d’un éclairage pertinent sur une technologie que nous ne maitrisions pas a priori ». L’efficacité de l’action de DocDoku a permis au client de réaliser qu’en quelques semaines, « le résultat est significatif (…) et nous permet de disposer d’une solution technique détaillée pour notre potentielle future mise en oeuvre ».
Introduire la composante indispensable au succès
En parallèle de la maîtrise technique, une autre composante de la réalisation a retenu l’attention du GIE AGORA : les qualités humaines des intervenants, qui ont été déterminantes dans ce projet.
Nicolas Cazottes évoque alors qu’en plus de ses compétences techniques, « le consultant DocDoku a su spontanément s’adapter au contexte qui demandait beaucoup d’autonomie et une intégration rapide dans l’équipe en place ». Il insiste sur le fait que le consultant était «pédagogue et très bon communiquant », des softskills très recherchées dans les contextes actuels et qu’il a su « générer des échanges riches et constructifs avec nos équipes en interne ».
Franchir avec succès une étape d’un projet de transformation passe donc par l’expertise et l’expérience du prestataire retenu. Mais l’approche humaine est également indispensable et doit s’inscrire dans une logique collaborative et d’accompagnement au changement.
Le pôle Innovation de l’UGAP (Union des groupements d’achats publics), première centrale d’achat publique française, a choisi d’intégrer DocDoku à son référencement des logiciels multi-éditeurs par l’intermédiaire de son partenaire SCC, leader des solutions de service d’infrastructures informatiques.
Notre plateforme de digitalisation des métierset process ainsi que l’ensemble de nos savoir-faire sont à présent plus visibles et immédiatement accessibles pour l’ensemble des acheteurs publics français – administrations et établissements publics de l’Etat, collectivités territoriales, établissements publics de santé et secteur social.
Ce référencement intervient dans le contexte actuel de mutation des organisations qui cherchent à se transformer en digitalisant leurs métiers afin de maîtriser leurs dépenses tout en soutenant les acteurs français de l’innovation.
La plateforme DocDokuPLM dispose des briques essentielles à l’innovation collective, en mesure de répondre aux enjeux de transformation des organisations dans toutes leurs spécificités. Nos capacités permettent ainsi de répondre à des besoins aussi divers que :
la digitalisation des ressources, pour un acteur public souhaitant par exemple gérer en ligne les contenus de ses programmes de formation,
l’optimisation de la communication, dans le but de permettre à des collaborateurs issus de services ou d’administrations différentes de collaborer en temps réel et en mode projet,
David Simplot, conseiller scientifique du président d’Inria, est intervenu sur l’historique de l’IoT et ses enjeux actuels.
Depuis 1967, l’INRIA – Institut National de Recherche en Informatique et en Automatique – accompagne les grandes mutations de la société par une recherche de pointe en sciences du numérique. Du développement durable à la recherche médicale en passant par la ville intelligente ou encore le véhicule autonome, l’INRIA met son expertise scientifique et ses applications à la disposition des entreprises.
Pour fêter ses 50 ans, INRIA a consacré ses dernières rencontres des 17 et 18 octobre derniers aux données et leurs applications : de la captation au stockage issu de l’internet des objets, jusqu’aux applications vidéo, image, robotique, en passant par les questions de sécurité et les innovations en terme d’apprentissage.
Origine de l’Internet des objets (IoT)
Pour David Simplot, conseiller scientifique du président d’Inria, la première utilisation du terme « IoT » est à attribuer au RIT (Rochester Institute of Technology) dans le cadre de ses recherches relatives au développement de la RFID (Radio Frequency Identification), un dispositif permettant de mémoriser et de récupérer des données à distance. Les capacités de la RFID, couplées à leur faible consommation (20 000 fois moins de puissance qu’une puce électronique), a ouvert la possibilité aux systèmes d’augmenter la vitesse de lecture des informations et la création de réseaux de capteurs et de noeuds communicants qui permettent de disposer d’un plus grand nombre d’informations en simultané via une station de base.
Aujourd’hui, le potentiel de l’IoT est immense, avec des projections de développement à plusieurs trillions de dollars de chiffre d’affaires d’ici 2025.
Xavier Barras, directeur des opérations de GS1 – association non gouvernementale initialement créée en 1972 pour répondre à la problématique de normalisation de l’usage des codes à barres – insiste sur le fait que la RFID a permis de connecter des objets qui n’avaient pas vocation à être connectés au départ, comme par exemple un pantalon dans un magasin.
3 grandes évolutions ont permis à l’IoT de se développer :
internet pour sa capacité de communication,
l’augmentation des capacités de stockage qui a permis d’augmenter le volume de données enregistrées,
la baisse des coûts d’accès.
Panorama des applications de l’IoT
L’INRIA travaille aujourd’hui sur 10 domaines d’application aux travers de ses 31 équipes Projet avec 15% de ses activités dédiées à l’IoT. Parmi les projets en cours, David Simplot évoque l’agriculture, avec l’utilisation de capteurs pour faire du prédictif contre le gel et protéger les cultures (illustration de la technologie prédictive par un autre exemple d’application ici ndlr), le tracking de conteneurs dans le transport maritime, la possibilité d’effectuer des inventaires en temps réel ou de géolocaliser des clients pour le Retail, dans la santé pour le tracking du matériel chirurgical… On other news, please checkout Truck Accident Attorney if you need legal help for accidents.
La société DECATHLON a été la première à utiliser des étiquettes RFID en magasin. L’usage n’était pas une finalité ou une contrainte mais bien le soutien d’une stratégie de commerce : inventaire en temps réel, possibilité ouverte de disposer d’une logique omnicanale et réassort facilité entre magasins.
Dans tout projet de déploiement IoT, 2 points importants à retenir :
Bien connaître son écosystème d’objets et savoir placer les capteurs de façon stratégique
Pour fonctionner, le Big Data a besoin de faire remonter un nombre très important de données. L’IoT, lui, a besoin de faire remonter les informations sans filtrage.
Grâce à l’IoT, l’usine devient de plus en plus agile. On parle aujourd’hui d’Industrie 4.0, où les capacités de production se déploient en fonction de ce que l’usine doit produire. AUDI, par exemple, a ouvert sa première « Smart Factory » au Mexique, où automatisation et personnalisation de la production sont maximales.
Au delà des usages en contexte de production, l’IoT – le Data Mining et le Big Data au global – poussent les acteurs à repenser leurs marchés et leurs modèles. L’enseigne de grande distribution Casino est devenue dernièrement prestataire de service en développant une activité autour de sa plate-forme intégrée de data consommateur.
Les défis de l’IoT
La standardisation est aujourd’hui difficile car la vision de la plupart des acteurs reste encore en silo et il n’existe pas de système d’exploitation générique. Le risque à court terme serait de se retrouver avec un acteur unique qui imposerait son modèle, alors que l’interêt serait davantage de faire émerger une norme commune entre tous les acteurs du secteur.
Aujourd’hui, 40 à 50% des budgets sont constitués de coûts de consolidation des données car la majorité des dispositifs ne sont pas interopérables, tant au niveau technique que sémantique. Comment retourner cette situation ?
La clé est de disposer d’un référentiel de qualité, gage de réussite pour éviter les problèmes de nommage, les redondances et les incohérences.
On pourra également se reposer sur le développement des modèles de données « pivot à pivot » – format standard permettant de fluidifier la communication – et le recours à des solutions intergicielles qui permettent de mixer plusieurs univers de données (un exemple d’approche ici ndlr).
En conclusion, les data et l’IoT en général ne sont pas des finalités : il s’agit de dépasser la notion d’Informatique comme centre de coût et d’y voir au contraire un centre de profit, en soutien du développement et de la stratégie de l’entreprise. « L’expertise se crée dans la mise en oeuvre, et pas uniquement dans l’apprentissage et l’experimentation » soulignent les intervenants qui insistent sur le fait que « Tout reste à imaginer. La limite, c’est notre propre imagination ».
Merci aux 450 participants du DevFest et bravo à nos équipes pour avoir suscité l’interêt de nos visiteurs lors de cette journée dédiée aux développeurs !
Une occasion pour l’écosystème toulousain de se retrouver et d’assister à des conférences de pointe sur l’évolution du métier de développeur, le développement mobile ou encore l’IoT.
Chez DocDoku, nous encourageons nos collaborateurs à prendre part à cette journée.
Plusieurs membres de nos équipes ont ainsi participé aux conférences : un réel atout pour renforcer leur veille technologique, réseauter et trouver de l’inspiration sur les méthodologies et outils de demain.
Un sondage auprès de 450 responsables de la transformation numérique d’entreprises provenant des Etats-Unis, du Royaume-Uni, de la France ou bien encore de l’Allemagne ont été questionnés récemment. Quelques chiffres ressortent de ce sondage :
54% affirment que les organisations qui ne suivent pas la transformation numérique feront faillite ou seront absorbées par un concurrent dans les quatre années à suivre.
89% des entreprises pensent que le changement de leur industrie passent par la technologie
On note également un soucis de gestion des données :
61 % des entreprises ont été incapables d’étendre les applications en fonction de la demande.
Seulement 19 % croient que leur base de données actuelle pourrait être compatible avec une nouvelle technologie comme la réalité virtuelle, la réalité augmentée et l’internet des objets.
Nous utilisons des cookies pour vous garantir la meilleure expérience sur notre site web. Si vous continuez à utiliser ce site, nous supposerons que vous en êtes satisfait.



































{kind=link}