MCP et Tools avec LangChain4j : la puissance des agents Java connectés au monde réel
Dans l’écosystème LangChain4j, deux concepts jouent un rôle décisif lorsqu’il s’agit de créer des agents capables d’interagir avec des services externes, d’exécuter des fonctions Java et de s’intégrer dans un workflow opérationnel : les Tools et le protocole MCP (Model Context Protocol). Ensemble, ils permettent aux LLMs d’aller bien au-delà de la simple génération de texte — ils deviennent opérationnels, connectés, augmentés.
Dans cette section, nous analysons comment LangChain4j implémente ces mécanismes et comment les exploiter efficacement, en illustrant chaque mécanisme avec une démo dont le code est récupérable par ssh :
git clone https://github.com/laurentjalletdocdoku/langchain4j-demos.git
🛠️ Tools : donner des super-pouvoirs au modèle via des fonctions Java
Les Tools représentent l’un des piliers de LangChain4j : ils permettent de déclarer des méthodes Java annotées que l’agent peut appeler automatiquement lorsqu’il détecte qu’une fonction correspond à l’intention de l’utilisateur.
➤ Définition d’un Tool
Dans LangChain4j, un Tool est simplement une méthode annotée :
public class GeoTools {
@Tool("Calculates the distance in km between two geographical points using the Haversine formula")
public double distanceBetweenCoordinates( @P("latitude of point A as double") double latA, @P("longitude of point A as double") double lonA, @P("latitude of point B as double") double latB, @P("longitude of point B as double") double lonB) { ...}
}
Le modèle obtient automatiquement :
- une description instructive,
- la signature du Tool,
- les paramètres explicités grâce à @P,
- la capacité de l’appeler de manière autonome lorsqu’une requête utilisateur demande ce type d’action.
➤ Exemple : donner des capacités géospatiales à un agent
On créé un GeoAgent utilisant les Geotools et un model Ollama avec Mistral.
L’agent n’a plus besoin d’être explicitement programmé pour choisir la fonction — le LLM choisit spontanément le Tool approprié en fonction du prompt.
Les Tools restent purement locaux : tout se passe dans la JVM.
Mais LangChain4j traite exactement ce type de fonction comme une “fonction de l’agent”, accessible par raisonnement du modèle.
🌐 MCP : connecter l’agent Java à un service externe
Si les Tools internes permettent déjà au modèle d’interagir avec des fonctions Java locales, le Model Context Protocol (MCP) élargit considérablement le champ des possibles.
Avec MCP, une API, un service métier, un moteur de recherche, une base de données ou n’importe quel système externe peut devenir — pour l’agent — un outil natif, utilisable aussi naturellement qu’une méthode Java annotée.
➤ Qu’est-ce que le MCP ?
Le Model Context Protocol est un standard conçu pour permettre aux agents LLM de dialoguer avec des services externes via un langage commun.
Son objectif est double :
- exposer des actions, des données ou des capacités métier sous forme de *Tools accessibles par le modèle ;
- garantir une interopérabilité fluide entre modèles, services web, microservices, systèmes internes ou ressources locales, sans logique d’intégration complexe.
Grâce à MCP, un service externe peut se présenter comme une extension directe des capacités du modèle.
Dans l’exemple, le serveur MCP expose un Tool permettant de récupérer les coordonnées géographiques d’une ville :
➤ Comment MCP s’intègre dans LangChain4j ?
L’un des points forts de LangChain4j est qu’il ne force pas un mode d’intégration rigide.
Tant que ton client Java respecte le protocole MCP (notamment le dialogue via STDIO et le formatage standardisé des messages), LangChain4j peut en faire un fournisseur de Tools.
Dans notre architecture :
- un McpClient est responsable de lancer le serveur MCP (par exemple un jar),
- la communication se fait via STDIN/STDOUT, comme prévu par le protocole,
- le client récupère dynamiquement la liste des Tools exposés par le serveur,
- LangChain4j injecte ensuite ces Tools dans l’agent, qui peut les appeler de manière totalement transparente.
Le modèle ne sait pas qu’un jar externe tourne derrière.
Il ne sait pas qu’un appel traverse un protocole, un pipeline STDIO ou un moteur JSON.
À ses yeux, il s’agit simplement d’un Tool supplémentaire, au même titre qu’une méthode Java annotée.
➤ Pourquoi MCP change la donne ?
MCP agit comme une couche d’abstraction universelle : il unifie les actions internes (Tools Java) et les actions externes (services, APIs, microservices) sous un même langage compréhensible par le modèle.
Résultats :
- les agents deviennent réellement plug-and-play,
- les capacités externes peuvent évoluer sans modifier le code Java,
- les LLM disposent d’un catalogue d’outils dynamiques, contrôlés et versionnés,
- l’écosystème devient modulaire et extensible.
Avec MCP, tes services deviennent des extensions intelligentes que l’agent peut orchestrer sans logique impérative.
C’est une brique essentielle pour bâtir des agents robustes, autonomes et interconnectés avec le monde réel.
🤖 L’agent complet : Tools + MCP = autonomie
Voici la construction de l’agent suivant: modèle Mistral servi par Ollama avec une classe de Tools et un client MCP.
ChatModel ollamaModel = OllamaChatModel.builder()
.baseUrl(ollamaBaseUrl)
.modelName(ollamaModelName)
.logRequests(true)
.build();
// launch the mcp server jar
McpTransport transport = StdioMcpTransport.builder()
.command(List.of("java", "-jar", mpcServerJarPath))
.logEvents(true)
.build();
McpClient mcpClient = DefaultMcpClient.builder()
.key("GeotoolsMCPClient")
.transport(transport)
.build();
ToolProvider toolProvider = McpToolProvider.builder()
.mcpClients(List.of(mcpClient))
.build();
GeoTools geoTools = new GeoTools();
GeoAgent geoAgent = AiServices.builder(GeoAgent.class)
.chatModel(ollamaModel)
.tools(geoTools)
.toolProvider(toolProvider)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.executeToolsConcurrently()
.build();
Ainsi l’agent dispose des capacités suivantes :
| Capacité | Origine | Mécanisme |
|---|---|---|
| Calcul de distances géographiques | Tool interne | Appel direct Java |
| Recherche de coordonnées d’une ville | MCP | STDIO |
| Chaînage automatique des deux | Agent LangChain4j | Sélection autonome du tool |
L’utilisateur peut donc écrire : « Calculate the distane in km between Toulouse and Barcelona ».
L’agent exécutera automatiquement la séquence suivante :
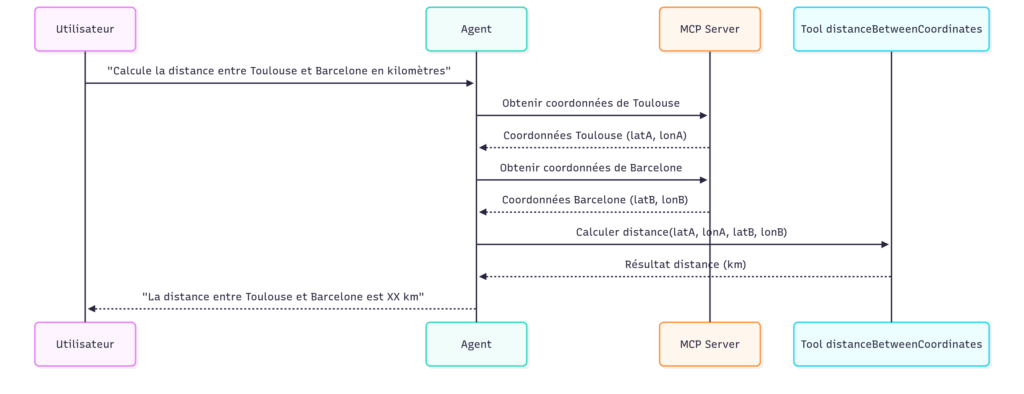
Calcul de la distance entre Toulouse et Barcelone
Sans logique conditionnelle dans le code.
Sans switch.
Sans règles manuelles.
C’est la promesse et la force combinée de LangChain4j, des Tools et du MCP.
🎯 Conclusion
Dans LangChain4j :
- les Tools permettent d’étendre le modèle avec des capacités Java locales,
- le MCP permet de connecter l’agent à des services externes normalisés,
- l’agent choisit automatiquement quand et comment appeler ces capacités.
L’exemple illustre cette synergie : un agent Java local, propulsé par un modèle Ollama, capable d’interroger un service MCP et d’effectuer des calculs avancés via des Tools. Une architecture simple, élégante et puissante.