DocDoku devient sponsor du 1er DevFest à Toulouse

DocDoku devient sponsor du DevFest à Toulouse
Pour la première fois, les locaux de l’IUT de Blagnac accueilleront un DevFest. Qu’est-ce qu’un DevFest ? C’est une conférence technique autour des technologies affiliées à Google (Web, Apps, Cloud, Objets connectés, Design, etc…). Au programme, 3 thématiques d’actualités : Web Apps, Mobile et Tools & Methods.
Evénement inédit dans la ville de Toulouse, DocDoku est heureux d’être sponsor de cette première dans la région.
Plus d’information et inscription sur le site dédié à l’évènement : https://devfesttoulouse.fr/
Retour sur l’EclipseCon France 2016 (partie 2)

Cet article fait suite à celui de Bertrand, afin de détailler certains sujets et présenter d’autres sessions auxquelles j’ai eu l’opportunité d’assister.
 Connecting low power IoT devices with LoRa, MQTT, and The Things Network
Connecting low power IoT devices with LoRa, MQTT, and The Things Network
De mon point de vue, l’IoT était vraiment à l’honneur cette année à Toulouse, notamment par la présence de The Things Network, ayant été invité par la Fondation Eclipse à donner un workshop et à tenir la première Keynote de la conférence.
Comme l’a mentionné Bertrand, cette équipe venue tout droit d’Amsterdam est en train de fédérer des communautés du monde entier autour de leur réseau dédié aux objets connectés, basé sur la technologie LoRa.
Alors qu’est-ce que LoRa ? Et qu’est-ce que The Things Network ?
LoRa
D’après le site de la LoRa Alliance (traduit par mes soins) :
LoRa est un diminutif pour LoRaWAN™: Low Power Wide Area Network (LPWAN).
LoRa est donc une spécification de communication sans fil basée sur les fréquences radio ISM (https://en.wikipedia.org/wiki/ISM_band).
Cette technologie est tout particulièrement adaptée comme couche de communication pour les objets connectés en ce qu’elle permet la localisation et la mobilité des appareils, à basse consommation, sans grosse installation de départ, ainsi qu’une communication bi-directionnelle.
Avec une simple antenne disposée en haut d’un immeuble en milieu urbain, ou dans un environnement plus dégagé, LoRa permet de connecter un nombre impressionnant d’appareils sans dégradation, bien plus qu’un routeur sans fil (WiFi, Bluetooth) et en consommant bien moins d’énergie et en étant moins onéreuse qu’un routeur 3G par exemple.
Quelques exemples d’utilisation:
- Réseaux électriques : prédire la consommation et produire de l’électricité en fonction des besoins réels
- Logistique : livraison avec une localisation plus précise
- Transport : appels d’urgence automatisés
- Santé : appareils de mesure de constantes
- Et tellement plus…
LoRa est en concurrence avec la technologie SigFox, que nous connaissons bien à Toulouse. Cependant son approche est différente, puisqu’à la différence de la technologie SigFox qui est propriétaire et induit des coûts de license, la spécification LoRa est libre.
Quelques relevés ayant été effectués par l’équipe de The Things Network, et autres caractéristiques :
- Environnement urbain dense : 500m à 3km
- Environnement rural : 10-50km (jusqu’à 92km lorsque très dégagé)
- Jusqu’à 10.000 appareils par routeur
- Jusqu’à 3 ans d’autonomie (à prendre avec des pincettes)
- Très basse consommation (et pas de « handshake »)
- License libre, en envoi et réception
- Pas de pré-requis à l’installation d’un tel réseau
- Couverture multiple (plusieurs routeurs peuvent relayer l’information).
Les appareils se connectant au réseau LoRa peuvent être classés en trois catégories :
- Liaison montante uniquement, l’appareil initie la communication et le serveur peut y répondre.
- L’appareil et le réseau se synchronisent sur une « fenêtre de tir » afin d’échanger des données.
- L’appareil est en écoute constante du réseau.
Evidemment les classes d’appareils influent sur leur consommation.
The Things Network
The Things Network est une initiative née à Amsterdam, pour construire un réseau mondial et libre permettant la communication entre objets connectés.
Après une campagne de crowfounding, les membres de l’équipe ont commencé la création d’une plateforme Web afin de permettre la connection d’appareils via des brokers.
Tout le code source applicatif de The Things Network est open source et disponible sur Github, pour aller de pair avec leur engagement pour permettre une vaste adoption de ces technologies.
En parallèle, une entité commerciale propose des Starter kits à visée éducative ainsi que des routeurs afin de permettre aux gens d’équiper leurs quartiers, leurs villes et d’initier le mouvement pour une couverture mondiale.
Des communautés existent déja de part le monde, principalement en Europe pour le moment. Ces communautés sont parfois à l’origine des membres de l’équipe de The Things Network, qui voyagent beaucoup afin de faire connaitre la technologie LoRa et leur projet, et parfois il s’agit d’initiatives spontanées.
A titre personnel, j’espère qu’une communauté verra le jour prochainement à Toulouse.
What every Java developer should know about AngularJS

Tout est dans le titre.
Cette session était dédiée aux développeurs plus habitués aux technologies backend et qui voulaient avoir une introduction au framework le plus en vogue actuellement côté frontend: AngularJS.
Ce workshop fut l’occasion de présenter succintement les controlleurs, les scopes, les services et autres directives, sous la forme d’un mini TP.
En tant que développeur fullstack ayant des bases d’AngularJS, je trouve que ce workshop a été bien mené, en plusieurs étapes afin d’itérer et d’introduire successivement de nouveaux concepts sur le petit cas concret présenté.
Les speakers ont même fait le choix de baser le code d’exemple sur TypeScript, afin de ne pas trop perturber leur audience plus habituée aux constructions objets classiques qu’à la spécification ECMAScript. Mes co-équipiers ont pu retrouver leurs petits dans un projet architecturé sur une base d’interfaces et d’implémentations, agrémenté de types génériques et autres héritages. Ils ont cependant eu affaire à la pauvreté du tooling Eclipse pour ce qui est du développement front.
Le tooling, parlons-en justement.
Tooling
Cette année les visiteurs ont pu assister à plusieurs sessions sur l’état des outils de développement intégrés à Eclipse. Voici un petit tour d’horizon des outils dont j’ai pu avoir un aperçu lors des sessions.
JSDT 2.0
Ce talk était dédié à la présentation du la nouvelle version des JavaScript Development Tools (JSDT), actuellement en cours de développement.
Les objectifs de JSDT 2.0 sont de supporter les méthodes et outils de l’état de l’art actuel du développement JavaScript moderne.
Actuellement, JSDT 2.0 profite d’un nouveau parseur bien plus efficace que le précédent, notamment capable de supporter la spécification ECMAScript 6.
Le reste des objectifs s’axent autour de l’intégration de gestionnaires de paquets (npm / bower), des « task builders » (grunt, gulp) ainsi que le support de Node.js et l’ajout d’outils de débugging et d’intégration avec les navigateurs, notamment Chrome.
The State of Docker and Vagrant Tooling in Eclipse
Chez DocDoku nous expérimentons déjà les outils Vagrant et Docker, notamment pour nos environnements de développement et d’intégration, afin de fournir à nos équipes une infrastructure immutable et des processus de déploiement répétables.
Dans cette présentation, j’ai pu avoir un aperçu de deux plugins, l’un pour l’intégration de Docker, et l’autre pour celle de Vagrant.
En l’état actuel, ces deux plugins présentent de nouvelles « perspectives » dans l’IDE Eclipse, qui permettent de faire tout (ou presque) ce qu’il est possible de faire en ligne de commande:
- Créer et gérer ses « box » Vagrant.
- Configurer son Vagrantfile.
- Créer et configurer ses machines virtuelles.
- Créer et gérer ses images Docker.
- Lister et manager ses containers Docker.
- Editer son Dockerfile.
Continuous Delivery: Pipeline As Code With Jenkins
Pour ma part, j’étais très curieux de voir ce qui allait être présenté dans ce talk. La perspective de pouvoir gérer ses builds sous forme de « pipelines » de traitements et la notion de « Continuous Delivery » (ainsi que le « Continuous Deployment » mais c’est un autre sujet) m’intéressent beaucoup.
Alors de quoi s’agit-t-il ? Principalement de ce que l’on pourrait décrire par la capacité d’orchestration, d’interruptibilité et de résilience de vos jobs de build. Rien que ça…
Comme décrit dans les slides de la présentation, que ce passe-t-il lorsque vous avez des jobs de build assez complexes, inter-dépendants, nécessitant des inputs d’opérateurs et éventuellement nécessitant de tourner en parallèle ?
Hormis le fait de créer de multiples jobs individuels que vous lierez par la suite en une cascade de builds à la chaîne, il n’y a pas de solution clé.
C’est ce problème que propose de résoudre le « Jenkins Pipeline Plugins », qui est en réalité un regroupement de plugins permettant d’orchestrer vos builds de manière plus fine. A la base de ce plugin se trouve un DSL, le « Pipeline DSL », qui permet de décrire l’enchainement des builds, sous forme d’étapes, et d’y attacher des options de configuration, comme le parallélisme pour n’en citer qu’une.
Il devient alors possible, par exemple, de configurer plusieurs dizaines de jobs similaires (à quelques variables près) formant de briques de bases (les dépendances d’un job de build suivant) et d’ordonner l’exécution de tous ces builds en parallèle, avant l’exécution du build suivant qui en dépend. Tout en spécifiant que la séquence de build complète doit stopper en cas d’échec d’un seul de ces builds de base (fail-fast).
Pour l’anecdote, le speaker a présenté exactement cet exemple, sur un cluster de build mis à sa disposition par un fournisseur « cloud » :
- 336 CPUs
- 1.032 TiB RAM.
Evidemment on a tous le même dans notre garage…
Quoiqu’il en soit, j’étais assez intrigué par le choix d’un DSL, en opposition à une description déclarative via des fichiers de configuration.
Il est assez facile d’imaginer comment décrire via des structures de données simples telles que des maps et des collections, l’orchestration d’un job, et la description de chacune de ses étapes.
Je n’ai pas eu de réponse claire à ce sujet, si ce n’est le poids de l’histoire : la plupart des contributeurs étant des développeurs Java, un DSL (très proche de Java d’ailleurs) semblait un choix logique.
Conclusion
Pour ma première participation à un évènement comme celui-ci, je dois dire que je suis conquis. L’organisation était parfaite et la qualité des intervenants largement satisfaisante.
J’aurai plaisir à participer de nouveau à l’EclipseCon, et je recommande à tout développeur ayant la possibilité de s’y rendre, d’y aller sans hésiter.
L’ensemble des vidéos des Keynotes et des sessions est à retrouver sur la chaine Youtube de la Fondation Eclipse, ici.
EDIT 26/07/2016:
Un nouvel article est apparu sur le site de Fondation au sujet du tooling Docker, le voici: http://www.eclipse.org/community/eclipse_newsletter/2016/july/article2.php
Retour sur l’EclipseCon France 2016

Comme l’an dernier nous étions présents à l’EclipseCon France, événement incontournable dans le milieu du logiciel libre à Toulouse. Cette année encore l’organisation était sans faille, avec une grande diversité de thèmes (modélisation, IoT, devops…), chacun représenté par des intervenants de grande qualité.
DocDoku était en effet présent afin d’y présenter sa plateforme DocDokuPLM. Ceci a donné lieu à de nombreux échanges avec des acteurs industriels de Toulouse, ce qui a permis de constater que nous sommes au coeur de problématiques essentielles telles que l’interopérabilité, l’ouverture de la plate-forme, la sémantique des modèles.
Retour sur quelques présentations auxquelles j’ai eu la chance d’assister.
La modélisation à l’honneur avec Sirius, Papyrus et Capella
La modélisation de logiciels ou de systèmes est une des problématiques majeures développées au sein de la fondation Eclipse.
Étaient présents cette années, entre autres, le CEA avec l’outil Papyrus, Obeo avec l’outil Sirius, et PolarSys avec l’outil Capella.
Chaque outil a ses particularités. Pour ma part j’ai assisté au workshop sur Sirius animé par une équipe très motivée et maîtrisant parfaitement son outil. Sirius a la particularité de permettre la définition de Domain Specific Languages pour ensuite définir des modèles dans ce langage de modélisation.
Mention spéciale à l’équipe du CEA qui est venue avec une véritable usine en Lego de fabrication de petites voitures (en Lego elles aussi), la partie logicielle étant modélisée à l’aide de Papyrus.

Un IoT open source et innovant avec LoRa
L’IoT était très bien représenté, avec notamment la présence de Benjamin Cabé, animateur du meetup IoT-Toulouse, et Johan Stokking, de The Things Network qui a pour but de développer un réseau mondial et libre permettant la collecte et l’échange de données provenant d’objets connectés.
réseau mondial et libre permettant la collecte et l’échange de données provenant d’objets connectés.
Ce projet est basé sur la technologie LoRa qui permet la communication à bas débit, par radio, alternative libre à SigFox, et soutenu par une alliance d’entreprises parmi lesquelles nous retrouvons Orange et Bouygues Télécom.
Eclipse Che : la révolution de l’environnement de développement
Eclipse Che, développé par Codenvy (connu pour son service d’IDE dans le cloud) est un outil permettant de gérer des environnements de développement virtualisés dans le cloud.
![]() Eclipse Che permet de mettre en place dans le cloud, non seulement un IDE, mais également un environnement d’exécution et de test automatisé du code.
Eclipse Che permet de mettre en place dans le cloud, non seulement un IDE, mais également un environnement d’exécution et de test automatisé du code.
Ceci permet de ne pas avoir à installer tout un environnement de développement/exécution/test sur la machine de chaque développeur. L’IDE en ligne renforce également le travail collaboratif : plusieurs développeurs peuvent éditer en même temps un même fichier (comme sur Google Docs).
L’équipe d’Eclipse Che est jeune et dynamique et de nombreuses améliorations sont à venir en ce qui concerne le pair programing et les tests JUnit.
TypeScript: du typage pour améliorer la scalabilité de JavaScript

Saurez-vous trouver les membres de DocDoku sur cette photo ?
TypeScript nous a été présenté par Sébastien Pertus, évangéliste technique chez Microsoft. TypeScript est en effet un projet libre développé par Microsoft, principalement par Anders Hejlsberg qui est aussi le principal inventeur de C#.
![]() Cette présentation était à la fois pleine d’humour et abordait des questions techniques pointues avec des démonstrations de programmation très pertinentes.
Cette présentation était à la fois pleine d’humour et abordait des questions techniques pointues avec des démonstrations de programmation très pertinentes.
TypeScript est à considérer comme un langage de programmation à part entière qui est trans-compilé en JavaScript. Ce nouveau langage ajoute à JavaScript de nombreuses fonctionnalités de typage comparables à ce qu’on retrouve dans le langage Java. On peut citer le typage statique, les classes, les interfaces…
De nombreuses fonctionnalités ajoutés par TypeScript sont maintenant présentes dans ECMAScript Edition 6, mais TypeScript conserve une longueur d’avance en proposant par exemple la notion de décorateur qui permet de programmer avec des annotations. D’autres améliorations sont prévues dans la future version de Javascript comme par exemple les non nullables types.
Tuleap : l’ALM open source
Enfin, l’aspect gestion de cycle de vie des applications/gestion de projet était également présent avec Tuleap développé par Enalean. Tuleap propose un outil de gestion de projet complet intégrant tous les aspects de tous les processus de développement (Cycle en V, Kaban, Scrum, Extreme Programming etc):
- Intégration des principaux systèmes de configuration (Git, SVN, CVS)
- Intégration continue (Jenkins)
- Wiki
- Revue de code
- Gestionnaire de bugs
- Gestionnaire de post-it configurable style Trello.
Encore un grand merci à tous les organisateurs et conférenciers de cet événement et à l’année prochaine !
2016 sera consacrée à coupler l’IoT avec notre plateforme DocDokuPLM
2016 sera consacrée à l’Internet of Things (IoT)
Comme nous l’avions en effet évoqué lors du SIANE 2015, salon des partenaires de l’Industrie du grand sud, sur lequel nous exposions au sein de l’espace de l’Usine du Futur, 2016 sera en effet consacrée à l’IoT pour DocDoku.
La problématique : comment compléter les données théoriques avec les données terrain ?
Notre équipe R&D continue en effet d’innover en travaillant sur une nouvelle brique de notre pateforme capable de rapprocher et d’analyser avec pertinence les données théoriques issues du PLM et les données captées en situation réelle (capteurs physiques restituant au travers d’un IoT gateway les données au PLM).
La demande des industriels pour l’usine du future nous conforte en effet dans notre effort pour compléter notre plateforme DocDokuPLM avec une brique dédiée notamment à la maintenance prédictive permettant ainsi d’améliorer la prédiction des pannes et d’anticiper les défaillances des équipements / produits. Mon prochain billet sera spécialement dédié à ce sujet.
Retour sur notre présence à la journée Stations de Montagne Connectées
Le 15 septembre dernier, nous avons pris la route aux côtés de Madeeli et de ses partenaires en direction de la CCI de Tarbes pour une journée de réflexion : « objets connectés et données, le nouvel or blanc des stations de montagne ? ».
Un territoire numérique
Plus de 80 acteurs issus de divers horizons (experts en TIC, gestionnaires de stations, spécialistes de l’aménagement de montagne, SSII) se sont ainsi réunis au cœur des Hautes-Pyrénées afin d’offrir les prémices d’un sujet aux enjeux précieux : la montagne numérique. Car au-delà des sommets enneigés, il s’agit bien d’une discussion de fond sur l’accès au numérique dans les territoires ruraux.
Zones blanches, altitude, humidité, froid … il n’y a pas à dire, la montagne est un territoire hostile aux technologies. Et pourtant, les stations de ski sont bien loin de ce qu’elles étaient il y a quelques années. Au début de la matinée, les intervenants d’AltiService, N’Py et Captronic se sont succédés pour nous présenter les technologies déployées en station.
On découvre alors que les grands domaines skiables font figure de modèle en termes d’innovations tournées vers l’usager : applications mobiles, flux d’informations en temps réel (météo, fréquentation), achats en ligne, bornes d’informations numériques, scanners de badges, webcams. Que les digital-addicts soient rassurés, leurs vacances à la neige ne les couperont pas du monde. Des espaces de détente wifi aux snowparks ultra connectés, tout est fait pour encourager la viralité.
L’automatisation des processus et des métiers a elle aussi bien démarrée. Les entreprises se succèdent dans la matinée et dans l’après-midi pour pitcher autour de leurs solutions innovantes. Capteurs, trackeurs, drones et autres balises GPS trouvent ainsi leur place sur les infrastructures et machines, récoltant des téraoctets d’informations par jour. Il est 14 heures, une introduction aux grands principes du Big Data marque le début de l’après-midi.

Solution d’aide à la maintenance 3.0 : DocDokuPLM
Dans un secteur encore dominé par le papier, l’absence de numérisation des documents est un réel obstacle. Disposer d’une solution de Gestion Electronique des Documents Techniques est un enjeu important pour les gestionnaires de stations. Bien que l’offre de capteurs connectés soit pléthorique pour les équipements, ils ne répondent pas seuls en totalité aux besoins en gestion de maintenance. Nous montons alors sur l’estrade pour présenter notre solution d’aide à la maintenance 3.0, apportant des réponses à deux problématiques :
- anticiper les risques de pannes,
- intervenir sur le terrain avec toutes les informations en main
Comment ?
En mettant à disposition des agents une plateforme mobile d’aide à la maintenance fournissant en temps réel :
- la documentation technique à jour de la machine (statut, assemblage, arbres de pannes, données des capteurs connectées, arbres statistiques…),
- l’historique des opérations de maintenance menées et à venir,
- un formulaire de saisie d’intervention.
Ainsi, les agents peuvent accéder rapidement aux informations relatives aux infrastructures telles que les remontées mécaniques, les dameuses, les canons à neige, les pylônes, les motoneiges…
La solution que nous avons présentée est DocDokuPLM, une plateforme digitale Open Source de gestion des données techniques et de maintenance disposant d’un Back Office opérationnel, structuré et adaptable.
Une fois l’équipement reconnu (par GPS, flash code, Bluetooth Low Energy…), DocDokuPLM met à la disposition des agents l’ensemble des informations le concernant (statut, documentation technique, historique de maintenance, maquette 3D). La solution garantit ainsi l’exactitude des informations fournies aux agents et donc améliore leur capacité à intervenir sur l’équipement.
Pour conclure, nous tenons à remercier Madeeli pour la très bonne organisation de cet événement, la CCI de Tarbes pour leur accueil, Digital Place qui nous a offert l’opportunité de prendre la parole lors de cette journée ainsi que l’ensemble des participants.
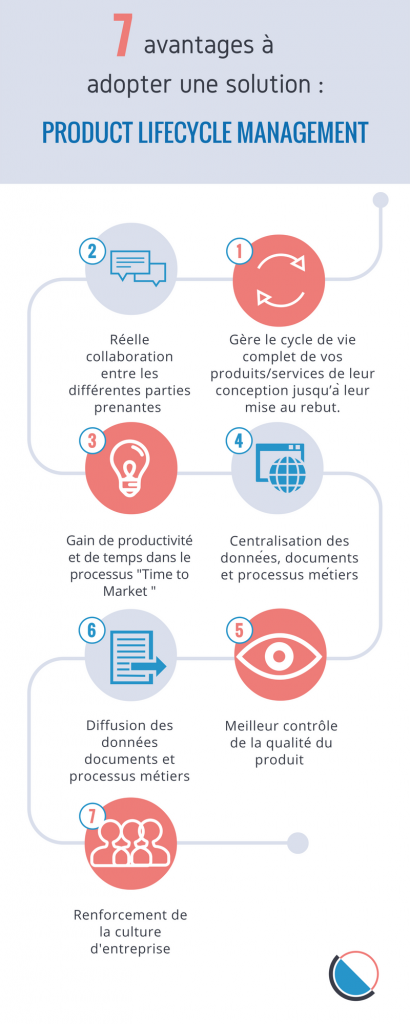
Comment utiliser les liens typés sur la plateforme DocDokuPLM ?
La structure produit est la structure d’assemblage qui décrit les liens physiques existants entre chaque composant d’un même produit. Mais comment peut-on mettre en évidence d’autres liens entre des articles ? Dans certains cas, on pourrait vouloir expliciter les relations électriques par exemple. En reliant les articles du point de vue électrique, on obtiendrait une autre structure de données s’apparentant davantage à un arbre de panne et permettant de régler les problèmes électriques plus facilement.
Grâce à la plateforme DocDokuPLM, vous pouvez définir différents arbres pour un même produit via les liens typés. Prenons l’exemple d’un bureau, voici sa structure produit complète :
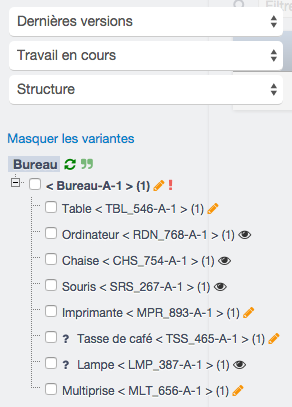
Comme on peut le voir, cette structure n’indique pas les liens électriques pouvant exister entre certains articles. Pour définir un lien entre 2 articles, sélectionnez-les dans l’arbre et cliquez sur le bouton « Liens typés ». Ensuite ajoutez un lien et renseignez le nom et la description du type. L’article source est le premier article que vous avez sélectionné dans la structure. L’article destination est le second. Au besoin, vous pouvez inverser ces 2 articles. N’oubliez pas d’enregistrer.
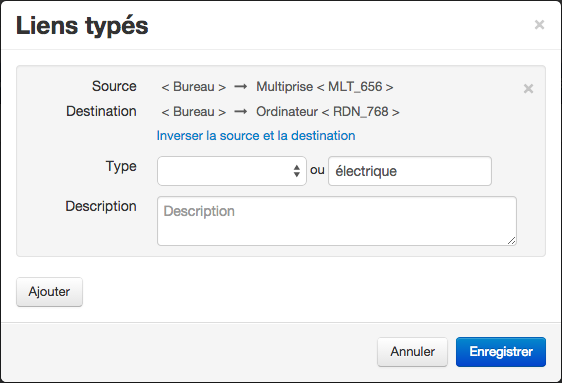
Chaque lien typé créé avec le type « électrique » fera partie d’un nouvel arbre. Sélectionnez ce type dans le menu de configuration en haut à gauche pour afficher les nouvelles connexions produit.
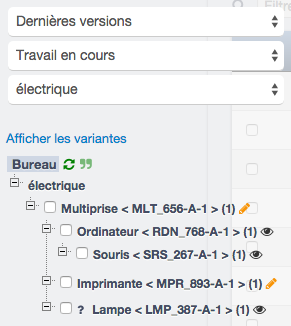
Ce nouvel arbre typé montre alors les liens électriques entre les articles et rend la correction de pannes électriques plus aisée.
Vous pouvez ajouter une infinité de liens typés entre 2 articles (des liens de type énergétique, de dépendances…). Par contre, il est impossible de créer une boucle (lien cyclique) avec le même type de lien. Dans ce cas, le système détecte la création d’un lien cyclique et la rejète automatiquement pour éviter une boucle infinie.
Retour sur notre présence à l’EclipseCon

La seconde édition de l’EclipseCon à Toulouse les 24 et 25 juin derniers, a réuni plus de 300 visiteurs et 18 exposants, tous accueillis dans une ambiance conviviale et chaleureuse par la responsable des relations partenaires, Perri Lavergne.
DocDokuPLM plébiscité par la communauté et la presse
En tant que partenaire de l’événement, aux côtés d’Obeo, IBM, Thales, Codenvy, Eurotech, Intel ou encore Red Hat, une conférence nous a été consacrée nous permettant ainsi de faire découvrir notre plateforme à la communauté Eclipse.
Parmi les visiteurs sur notre stand, nous avons eu un échange passionnant avec Eike Stepper, Consultant Senior IT Software Architect, au sujet du projet CDO (Connected Data Objects) sur la comparaison de graphes dont l’implémentation serait appropriée aux Product Breakdown Structure de notre plateforme.
Nous avons également échangé avec Wayne Beaton, Directeur des projets Open Source de la Fondation Eclipse, au sujet de l’étendue de l’écosystème Eclipse et de ses nombreuses applications dans l’industrie.
Enfin, les journalistes de Linux Magazine et de L’embarqué étaient également au rendez-vous et en ont profité pour en savoir davantage sur DocDokuPLM.
Des conférences autour de projets novateurs Eclipse
Parmi les différentes conférences données lors de la convention, nous avons pu assister à celle du projet Oomph: l’installateur Eclipse. Celui-ci permet aux nouveaux utilisateurs dès leur première utilisation, des fonctionnalités poussées d’Eclipse. Permettant ainsi une installation très facile et des mises à jour automatisées, l’installateur est aussi capable de paramétrer très facilement son environnement de travail.

Un autre projet très prometteur nous a été présenté: Eclipse Che. Il existe déjà depuis quelques temps, et la société Codeenvy offrant une plateforme de développement nous a présenté tout son potentiel.

En couplant Eclipse Che à Docker, logiciel open source qui automatise le déploiement d’applications dans des conteneurs logiciels, Codeenvy propose un environnement de travail en ligne, déjà paramétré pour tout nouvel utilisateur. L’utilisation via github étant déjà intégré par le système de pull request (demande de validation de mise à jour), cet outil pourrait être l’avenir pour les projets open source.
Nous avons enfin assisté à des conférences autour d’Eclipse sur notamment de nouveaux plugins, l’intégration des technologies IoT dans Eclipse, la communauté et comment participer au projet. Nous avons particulièrement apprécié la conférence sur la place de l’informatique dans les énergies renouvelables : comment celles-ci peuvent-elles répondre aux problématiques que posent l’intégration des énergies renouvelables dans notre consommation et quelles sont les perspectives que l’on peut avoir à court et long terme ?
Pour finir, nous souhaitons remercier l’équipe de la Fondation Eclipse ainsi que les intervenants pour leur accueil et leur dynamisme.
Projet d’innovation : revue de conception produit en temps réel sur le web
Depuis début 2014, nous travaillons en collaboration avec l’IRIT et plus particulièrement l’équipe Vortex, sur un projet de recherche appliquée dans le cadre de l’appel à projets régional Agile IT 2013.
Objectif du projet
L’objectif de ce projet était de créer un Environnement Virtuel Collaboratif (EVC) rendant accessible, manipulable et modifiable la maquette numérique des produits à tous les métiers de l’entreprise.
D’un point de vue logiciel, il s’agissait donc de développer le module web pour :
- la visualisation collaborative 3D web temps réel,
- l’édition et la manipulation web de pièces 3D.
Utilisable depuis un navigateur internet, sans qu’il soit nécessaire d’installer le moindre plugin, ce composant logiciel fait donc partie intégrante de notre plateforme digitale open source DocDokuPLM.
Fonctionnalités et bénéfices
Bien plus qu’un simple partage d’écrans, notre plateforme permet donc désormais à la fois de réaliser le design du produit en 3D tout en gérant son cycle de vie depuis le même outil, accessible de n’importe où au travers de votre navigateur.
Véritablement extensible, ce module permet de gérer plusieurs EVC (room en anglais) avec plusieurs utilisateurs simultanés. Entièrement développé grâce aux nouveaux standards du Web, ce dernier ne nécessite aucune installation complémentaire.
De plus, ce module offre toute la sécurité que l’on peut en attendre : les participants invités sur l’EVC (ou la room) pour la revue n’auront jamais accès aux documents ou articles sur lesquels ils n’ont pas les droits d’accès.
La vidéo ci-dessous (filmée par téléphone) montre l’utilisation de cette fonctionnalité.
L’ordinateur de droite initie la réunion de groupe (EVC ou room) et invite les utilisateurs connectés (sur l’autre PC à gauche).
Nous vous invitons également à découvrir gratuitement tout cela en créant un compte et un espace de travail sur notre plateforme cloud : http://www.docdokuplm.net
DocDoku s’implante sur Paris
Après s’être implanté sur Lyon à la fin de l’année 2014, nous avons aujourd’hui fait le choix d’être au plus près de nos clients en renforçant notre présence sur Paris.
Dès aujourd’hui, nous dispensons l’intégralité de nos formations dans nos locaux parisiens situés au 5 rue Castiglione 75001 Paris.
Toute l’équipe sera ravie de vous accueillir pour de nouvelles formations.
[wpgmza id= »1″]
Le meilleur d’AngularJS et de Cordova : ngCordova

{kind=link}
ngCordova
Si vous voulez développer rapidement une application Phonegap/Cordova sans vouloir utiliser toute la stack mean.io ou ionic, je vous conseille vivement ngCordova.
L’idée est d’encapsuler des plugins Phonegap/Cordova dans des services AngularJS. Mais dans quel but exactement… ?
Ne pas ré-inventer la roue
Bénéficiant d’une communauté active, ngCordova implémente la plupart des plugins nécessaires (photo, network, vidéo…). Trouver son bonheur parmi tous ces plugins n’est donc pas chose difficile. En quelques étapes d’installation, notre plugin est prêt à être utilisé et s’intègre parfaitement dans nos contrôleurs AngularJS. Pas besoin donc de créer soi-même l’encapsulation de ces services, si ce n’est pour savoir le faire.
Installation
L’installation de ngCordova se fait de la même façon que n’importe quel autre composant bower.
bower install ngCordova
Les sources sont téléchargées et copiées dans le sous-répertoire bower_components.
bower_components/ngCordova/
├── bower.json
├── CHANGELOG.md
├── dist
│ ├── ng-cordova.js
│ ├── ng-cordova.min.js
│ ├── ng-cordova-mocks.js
│ └── ng-cordova-mocks.min.js
├── LICENSE
├── package.json
└── README.md
Les sources de ngCordova sont maintenant prêtes à être injectées dans votre application AngularJS. Pour cela, il faut renseigner le fichier dans index.html et la dépendance dans votre fichier app.js.
index.html
<script src="lib/ngCordova/dist/ng-cordova.js"></script>
<script src="cordova.js"></script>
app.js
angular.module('myApp', ['ngCordova'])
Et voila !
Utilisation
Tous les services ngCordova sont directement injectables dans vos composants AngularJS, par exemple pour utiliser le service des dialogues :
module.controller('MyCtrl', function($scope, $cordovaDialogs) {
$cordovaDialogs.alert('message', 'title', 'button name')
.then(function() {
// Le bouton a été cliqué, écrire le code correspondant ...
});
});
Et c’est la même chose pour tous les autres services : autre exemple pour utiliser le service de fichiers et des photos :
module.controller('MyCtrl', function($scope, $cordovaFile) {
$cordovaFile.getFreeDiskSpace()
.then(function (success) {
// success in kilobytes
}, function (error) {
// error
});
});
module.controller('MyCtrl', function($scope, $cordovaMedia) {
var media = $cordovaMedia.newMedia("/src/audio.mp3").then(function() {
// success
}, function () {
// error
});
media.play();
});
Il devient alors très facile d’imbriquer tous ces composants afin de construire une application HTML5 riche. Toutes les fonctionnalités de base sont couvertes et sont disponibles sur Github.
ngCordovaMocks
Tester son code sur du vrai matériel n’est pas toujours possible. Pour cela, il nous faut une solution pour tester ses composants sur notre navigateur préféré. C’est là qu’intervient ngCordovaMocks.
Comme son nom l’indique, cette librairie vas nous permettre de “mocker” les appels à certains services.
L’installation se fait de la même manière que pour ngCordova : via bower.
bower install ng-cordova-mocks
Ensuite, il faut rajouter le script dans sa page :
<script src="lib/ngCordova/dist/ng-cordova-mocks.js"></script>
Et dans son fichier app.js :
angular.module('myApp', ['ngCordovaMocks'])
Ceci dit, on ne peut pas ajouter ngCordova et ngCordovaMocks sur la même page, et il devient très pénible de devoir changer ces deux lignes à chaque changement d’environnement. Pour cela on va utiliser gulp (site officiel) et son plugin gulp-preprocess (npm) pour éviter de le faire manuellement. Pour une installation et utilisation de gulp, voir cet article.
La page html devient alors :
<!-- @if NODE_ENV='DEVICE-DEVELOPMENT' -->
<script src="lib/ngCordova/dist/ng-cordova.js"></script>
<!-- @endif -->
<!-- @if NODE_ENV='DESKTOP-DEVELOPMENT' -->
<script src="lib/ngCordova/dist/ng-cordova-mocks.js"></script>
<!-- @endif -->
Le fichier app.js devient :
// @if NODE_ENV == 'DEVICE-DEVELOPMENT'
angular.module('myApp', ['ngCordova'])
// @endif
// @if NODE_ENV == 'DESKTOP-DEVELOPMENT'
angular.module('myApp', ['ngCordovaMocks'])
// @endif
Et le gulpfile associé :
gulp.task('device-development', function() {
gulp.src('./www/gulp_preprocess_me/*.js')
.pipe(preprocess({context: { NODE_ENV: 'DEVICE-DEVELOPMENT'}}))
.pipe(gulp.dest('./www/js/'));
gulp.src('./www/gulp_preprocess_me/index.html')
.pipe(preprocess({context: { NODE_ENV: 'DEVICE-DEVELOPMENT'}}))
.pipe(gulp.dest('./www/'));
});
gulp.task('desktop-development', function() {
gulp.src('./www/gulp_preprocess_me/*.js')
.pipe(preprocess({context: { NODE_ENV: 'DESKTOP-DEVELOPMENT'}}))
.pipe(gulp.dest('./www/js/'));
gulp.src('./www/gulp_preprocess_me/index.html')
.pipe(preprocess({context: { NODE_ENV: 'DESKTOP-DEVELOPMENT'}}))
.pipe(gulp.dest('./www/'));
});
En une ligne de commande vous pouvez maintenant choisir d’utiliser la libriaire ngCordova pour un développement sur mobile, ou bien ngCordovaMocks pour un développement sur desktop.
gulp device-development
gulp desktop-development
Attention quand même au déploiement : ne surtout pas envoyer la librairie des mocks en production 🙂
Conclusion
Pour rapidement utiliser ngCordova et ses plugins, une phase de configuration et d’outillage est nécessaire et peut s’avérer un peu longue. Néanmoins, une fois cette étape réalisée, l’installation de nouveaux plugins, leur utilisation, et leur déboggage sont très simplifiés. Toutes les documentations sont disponibles sur http://ngcordova.com/docs/plugins/ et sur les dépôts des plugins. Maintenant, à vos claviers…
DocDoku rencontre les industriels au salon de l’industrie 2015

Le salon de l’industrie 2015 a regroupé, au parc des expositions de Lyon, près de 20 500 professionnels des technologies de production.
Confirmation de l’adoption massive des robots notamment intégrés auprès des équipements de productions et machines à commandes numériques pour améliorer le chargement des pièces et outils, et l’efficacité des approvisionnements.
Même tendance dans l’automatisation des postes d’assemblage par les robots.
Il semble également que la chaine d’automatisation commence toujours par la commande papier avec scan du code-barre de cette dernière.
Accent sur l’innovation avec un prix spécial accordé pour un robot collaboratif d’Akéo-Plus capable de déplacer des boîtes de poids et de taille variables tout en détectant les personnes à proximité et en contournant les obstacles.
La transformation numérique des équipementiers industriels est en marche mais reste centrée à l’adoption d’ERP et d’intégration de fonctionnalités numériques autour de la CFAO.
Il semble qu’une fracture numérique apparait entre les grands équipementiers investissant dans l’usine intégrée du futur et les ETI/PMI conservant une approche plus traditionnelle (non digitale) en matière de processus métier autour de leurs produits.
Certains intégrateurs métier, comme les experts en programmation de commandes numérique, souhaitent d’ailleurs compléter leurs offres avec l’utilisation de la maquette numérique en le lien avec les bureaux d’études.
Ces constats confirme que DocDoku est idéalement positionnée pour apporter les solutions digitales nécessaires aux organisations industrielles.
Notre plateforme digitale collaborative répond en effet aux besoins des PMI/ETI industrielles voulant évoluer rapidement et simplement vers la gestion électronique des documents techniques, puis vers la gestion de leurs produits, et de manière homogène et logique.
Les rencontres avec les industriels et les intégrateurs ont été prometteuses d’opportunités. Je vous recommande donc ce très bon salon pour l’année prochaine.
Le point sur le Compte Personnel de Formation (CPF)
Le Compte Personnel de Formation (CPF)
Mesure phare de la réforme de la formation professionnelle, le Compte Personnel de Formation (CPF) a été mis en place depuis le 1er janvier 2015 en remplacement du Droit Individuel à la Formation (DIF).
Cette réforme doit permettre d’optimiser l’accès des salariés à la formation. Toutefois, ce changement ne concerne pas uniquement les personnes exerçant une activité professionnelle. Les chômeurs ainsi que les jeunes diplômés peuvent en effet désormais en bénéficier.
Quelles différences avec son prédécesseur le DIF ?
Le CPF fonctionnera quasiment comme le Droit Individuel à la Formation (DIF) à quelques différences près. Contrairement à son prédécesseur, le CPF est attaché à l’individu et non plus à un contrat de travail. Il le suit donc dès son entrée dans la vie professionnelle, à partir de l’âge de 16 ans, et ce, jusqu’à son départ en retraite. Ainsi, il l’accompagne même au cours de ses périodes de chômage.
Quelles formations sont éligibles au CPF ?
Sont prises en compte par le CPF, les formations faisant partie :
- du socle de connaissances et de compétences (contenu défini par décret)
- de l’accompagnement à la VAE
Ainsi que les formations :
- qui conduisent à une certification RNCP (Répertoire National des Certifications Professionnelles),
- qui conduisent à un CQP ou CQPI (Certificat de Qualification Professionnelle et Certificat de Qualification Professionnelle Inter-branches),
- inscrites à l’inventaire des certifications personnelles par la CNCP (Commission Nationale de la Certification Professionnelle) entrant dans le programme régional de qualification.
Des listes de formation encore incomplètes
Aujourd’hui, beaucoup de listes sont encore en cours d’enregistrement. En consultant son compte sur http://www.moncompteformation.gouv.fr/ les résultats que peuvent donner une recherche restent donc partiels. En effet, plusieurs domaines tels que la programmation informatique ne sont pas encore référencés et donc pas consultables dans le cadre de ce dispositif.
Les tests unitaires avec Mockito
Les tests unitaires
Egalement appelés « TU », ils sont destinés à tester une unité du logiciel. Afin d’être vraiment unitaires, ils doivent être en totale isolation pour ne tester qu’une classe et qu’une méthode à la fois.
Tester le bon comportement de son application c’est bien, détecter les éventuelles régressions c’est encore mieux ! Et c’est là que réside tout l’intérêt d’écrire des TU.
De la théorie… à la bonne pratique
Un test unitaire doit être véritablement unitaire. Pour cela, les appels aux services, aux bases de données et fichiers doivent être évités. Le TU doit s’exécuter le plus rapidement possible afin d’avoir un retour quasi immédiat.
Un TU faisant partie intégrante du code applicatif, les pratiques suivantes sont recommandées :
- il doit respecter les conventions de code
- il doit être simple et lisible,
- il ne doit tester qu’un seul comportement à la fois
- il doit faire le moins d’appel possible aux dépendances
- l’utilisation de mocks est recommandée pour fiabiliser les TU.
Un mock est un objet qui permet de simuler un objet réel tel que la base de données, un web service…
L’approche TDD (Test Driven Development) reste la meilleure solution pour éviter que les tests soient écrits à la fin du développement de l’application.
Frameworks de mock
L’écriture d’objets de type mock peut s’avérer longue et fastidieuse, les objets ainsi codés peuvent contenir des bugs comme n’importe quelle portion du code. Des frameworks ont donc été conçus pour rendre la création de ces objets fiable et rapide.
La plupart des frameworks de mock permettent de spécifier le comportement que doit avoir l’objet mocké avec :
- les méthodes invoquées : paramètres d’appel et valeurs de retour,
- l’ordre d’invocation de ces méthodes,
- le nombre d’invocations de ces méthodes.
Les frameworks de mock permettent de créer dynamiquement des objets généralement à partir d’interfaces ou de classes. Ils proposent fréquemment des fonctionnalités très utiles au-delà de la simple simulation d’une valeur de retour comme :
- la simulation de cas d’erreurs en levant des exceptions,
- la validation des appels de méthodes,
- la validation de l’ordre de ces appels,
- la validation des appels avec un timeout.
Plusieurs frameworks de mock existent en Java, notamment :
- EasyMock,
- JMockIt,
- Mockito,
- JMock,
- MockRunner.
Dans ce qui suit, nous allons détailler le framework Mockito.
Mockito

C’est un framework Java très connu permettant de générer automatiquement des objets ‘mockés‘. Couplé avec JUnit, il permet de tester le comportement des objets réels associés à un ou des objets ‘mockés’ facilitant ainsi l’écriture des tests unitaires.
Configuration du projet
Pour intégrer Mockito à son projet, il suffit simplement de rajouter la dépendance Maven :
<dependency>
<groupid>org.mockito</groupid>
<artifactid>mockito-all</artifactid>
<version>1.9.5</version>
</dependency>
Deux manières sont possibles pour intégrer Mockito dans les tests Junit :
1- Ajouter l’annotation @RunWith (MockitoJunitRunner.class) à la classe de test :
@RunWith(MockitoJunitRunner.class)
public class MyTestClass {
}
2- Faire appel à la méthode initMocks dans la méthode de SetUp :
@Before
public void setUp() {
MockitoAnnotations.initMocks(this);
}
Création d’objets mockés avec @Mock
La création d’objets mockés se fait soit en appelant la méthode mock(), soit en rajoutant l’annotation @Mock pour les instances de classes.
User user = Mockito.mock(User.class);
ou
@Mock
User user;
Mockito encapsule et contrôle tous les appels effectués sur l’objet User. Ainsi user.getLogin() retournera tout le temps null si on ne « stubb » pas la méthode getLogin().
Définition du comportement des objets mockés ou « Stubbing »
Le stubbing permet de définir le comportement des objets mockés face aux appels de méthodes sur ces objets. Plusieurs méthodes de stubbing sont possibles :
- Retour d’une valeur unique
Mockito.when(user.getLogin()).thenReturn(‘user1’); //la chaine de caractères user1 sera renvoyée quand la méthode getLogin() sera appelée.
- Faire appel à la méthode d’origine
Mockito.when(user.getLogin()).thenCallRealMethod();
- Levée d’exceptions
Mockito.when(user.getLogin()).thenThrow(new RuntimeException());
Il faut noter que la méthode retournera toujours la valeur stubbée, peu importe combien de fois elle est appelée . Si on stubb la même méthode ayant la même signature plusieurs fois, le dernier stubbing sera pris en compte.
Mockito.when(user.getLogin()).ThenThrow(new RuntimeException()).ThenReturn(« foo »);
Ici le premier appel va lever une exception, tous les appels qui suivront retourneront « foo ».
- Retours de valeurs consécutives
Mockito.when(user.getLogin()).thenReturn(‘user1’,’user2’,’user3’);
Le premier appel retourne user1, le deuxième retournera user2 le troisième user3. Tous les appels qui suivent retourneront la dernière valeur c’est à dire user3.
- Ne rien retourner
Mockito.doNothing().when(user.getLogin());
Espionner un objet avec @Spy
Au lieu d’utiliser l’annotation @Mock, nous pouvons utiliser l’annotation @Spy. La différence entre les deux réside dans le fait que la deuxième permet d’instancier l’objet mocké, ce qui peut être très utile quand nous souhaitons mocker une classe et non pas une interface.
Une autre différence est à signaler est le stubbing. Si nous ne redéfinissons pas le comportement des méthodes de l’objet espionné, les méthodes réelles seront appelées, alors qu’avec @Mock, nous sommes obligés de spécifier leurs comportements, sinon la valeur nulle est retournée par défaut. Dans l’exemple qui suit la méthode getLogin() sera appelée.
@Spy
User user = new User(‘user1’);
user.getLogin() // retourne user1
Vérification d’interactions @Verify
@Verify permet de vérifier qu’une méthode a été bien appelée et que que les interactions avec le mock sont celles attendues.
Nous pouvons également vérifier le nombre total de fois ou la méthode a été appelée (atMost(3),atLeastOnce(),never(),times(5)) , l’ordre des invocations des objets mockés en utilisant inOrder() et aussi vérifier si une méthode a été invoquée avant la fin d’un timeout. Nous pouvons également ignorer les appels stubbés en utilisant ignoreStubs() et aussi vérifier qu’il n y’a pas eu d’interaction en utilisant verifyNoMoreInvocations().
verify(user).getLogin();
//le test passes si getLogin() est appelée avant la fin du timeout
verify(mock, timeout(100)).getLogin();
Injection
Mockito permet également d’injecter des resources (classes nécessaires au fonctionnement de l’objet mocké), en utilisant l’annotation @InjectMock. L’injection est faite soit en faisant appel au constructeur, soit en faisant appel au ‘setter’ ou bien en utilisant l’injection de propriétés.
public Class DocumentManagerBeanTest{
@Mock EntityManager em;
@Mock UserManager userManager;
@Spy RoleProvider role = new RoleProvider();
@InjectMocks DocumentManagerBean docBean;
@Before public void initMocks() {
MockitoAnnotations.initMocks(this);
}
@Test
public void uploadDocument(){
docBean.uploadDoc(file);
}
}
public Class DocumentManagerBean {
private EntityManager em;
UserManager user;
RoleProvider role
public String uploadDoc(String file){
if (user.hasAcess()){
em.checkFileExists(file);
….
}
}
}
Conclusion
Mockito est un framework de mock qui, associé à Junit, permet :
- une écriture rapide de tests unitaires,
- de se focaliser sur le comportement de la méthode à tester en mockant les connexions aux bases de données, les appels aux web services …
Cependant il a certaines limitations, en effet , il ne permet pas de mocker :
- les classes finales,
- les enums,
- less méthodes final,
- les méthodes static,
- les méthodes privées,
- les méthodes hashCode() et equals().
Aussi, les objets ‘mockés’ doivent être maintenus au fur et à mesure des évolutions du code à tester.
Architecturer ses applications JS à l’aide du pattern MVVM
Pourquoi imposer une architecture à nos applications ?
Nos projets en JavaScript deviennent de plus en plus complexes : par leur taille, par leur fonctionnement et par leur coût de développement.
Le nombre d’outils et de librairies accessibles aux développeurs ne cesse de grandir et ce n’est pas en 2015 que la cadence va s’arrêter. Il est donc de plus en plus facile de se perdre et de rendre notre code illisible, difficilement maintenable et évolutif.
Toute notre problématique est là : rendre nos applications scalables pour les :
- Maintenir
-> Facilement améliorer le code courant
-> Rendre son code compréhensible de tous
- Adapter
-> Inclure de nouvelles librairies
-> Etendre, changer des parties
- Debugger
-> Tester chaque partie de manière indépendante
- Développer plus rapidement
-> Chaque développeur peut travailler en parallèle.
Le pattern MVVM va nous aider à résoudre ces problèmes tout en nous simplifiant la vie.
Pattern MVVM
Le pattern MVVM est un dérivé du célèbre modèle de conception MVC.
L’ancêtre MVC
L’idée principale du MVC, signifiant Model-View-Controller, est de découper l’application en trois parties interconnectées :
- Model: représente les données reçues du serveur
- View: contient l’ensemble des vues affichées à l’utilisateur
- Controller: contient la logique de l’application

Le Modèle définit la structure des données et communique avec le serveur.
La Vue affiche les informations du Modèle et reçoit les actions de l’utilisateur.
Le Contrôleur gère les évènements et la mise à jour de la Vue et du Modèle.
Nous avons un premier découpage de l’application qui nous permet déjà de répondre à certaines de nos problématiques. En identifiant clairement les parties logiques, nous pouvons plus facilement maintenir notre application et la tester.
Mais qu’en est-il de l’adaptation et de l’évolution de notre application ? Si le modèle de données est amené à changer, nous devons obligatoirement modifier l’ensemble de nos entités.
Qu’apporte alors le pattern MVVM et que signifie-t-il ?
Principes du MVVM
MVVM est l’acronyme de : Model-View-ViewModel.
On pourrait donc simplement croire qu’on a remplacé le nom Controller par ViewModel. Mais si nous reprenons le schéma précédent avec le pattern MVVM, nous obtenons les interactions suivantes :

La Vue reçoit toujours les actions de l’utilisateur et interagit seulement avec le ViewModel.
Le Modèle communique avec le serveur et notifie le ViewModel de son changement.
Le ViewModel s’occupe de :
- présenter les données du Model à la Vue,
- recevoir les changements de données de la Vue,
- demander au Model de se modifier.
Data Binding
La Vue n’a donc plus aucun lien avec le Model. Ainsi le ViewModel s’occupe entièrement du cycle de modification de ce dernier. Il réalise à la fois la réception et l’envoi des données à la Vue. On parle alors de « data binding ». Les informations affichées sont liées entre deux entités et mises à jour en temps réel.
Ce dernier mécanisme est la clef du pattern MVVM. Il nous permet de découpler les différentes parties de notre application en étant capable de la faire évoluer de manière modulaire.
Dans le schéma suivant, nous pouvons voir qu’un même Modèle peut notifier plusieurs ViewModel de son changement. Ainsi ces ViewModel vont à leur tour indiquer à leur Vue de se rafraîchir.

Si la Vue n°2 modifie le Model, la Vue n°1 sera automatiquement mise à jour.
Du fait de cette indépendance entre la Vue et le Modèle, nous pouvons modifier ou remplacer les différents composants visuels sans impacter le cœur de notre application. Nous pouvons également changer, améliorer la logique de notre application à travers le ViewModel sans toucher à la Vue et au Model.
Presenter
Le pattern MVVM est également cité comme une extension du MVP : Model-View-Presenter.
La structure de données que nous recevons du serveur n’est pas forcément celle à afficher à l’utilisateur. Il est néanmoins conseillé de garder cette structure initiale pour pouvoir l’exploiter à d’autres moments. Le ViewModel peut présenter à la Vue, une autre structure ou des données formatées différemment.
Cet aspect du MVVM va nous permettre de facilement modifier nos services et donc notre Modèle sans toucher à la Vue. Seul le ViewModel devra se réadapter pour fournir à la Vue les mêmes informations.
Un autre avantage est la possibilité de mocker nos Webservices dans le ViewModel. Ainsi nous pouvons travailler sur notre IHM en parallèle de la mise en place de nos WebServices.
Implémentations
Il existe de nombreux frameworks Javascript, qui permettent de développer des applications MVVM et qui fournissent des outils pour réaliser un data-binding.
Voyons comment au travers de trois frameworks : KnockoutJS, AngularJS et ExtJS, nous pouvons créer une application TodoList. Notre exemple sera volontairement simple pour faire apparaître les différents mécanismes du MVVM.
Notre application sera composée de deux vues :
Vue 1 :
Un formulaire d’édition composé de :
– Un bouton : au clic une nouvelle tâche est ajoutée.
– Un input texte : affiche et édite la tâche en cours.
– Un label : affiche le nombre de tâches.
Vue 2 :
Une liste de label : chaque label affichera le titre d’une tâche.
Au clic sur un label, la tâche courante sera modifiée pour afficher dans le formulaire, le titre sélectionné.
Notre modèle sera composé de deux « classes » :
Une classe Task, pour définir une tâche, composée d’un titre
Une classe Setting contenant :
– La tâche courante à éditer.
– La liste de toutes les tâches crées.

KnockOutJS
KnockoutJS est une libraire Javascript, qui peut facilement s’intégrer à une architecture déjà existante. Elle propose plusieurs outils pour simplifier et automatiser la mise à jour de l’UI lorsque les données changent.
Model
On définit les deux classes. Chaque propriété doit être attribuée à partir des méthodes « observables » de KnockOutJS. L’appel à ces méthodes va permettre d’enregistrer ces données pour écouter leur modification.
var Task = function (title, index) {
this.title = ko.observable(title);
};
var Setting = function() {
var task = new Task("new task");
this.currentTask = ko.observable(task);
this.tasks = ko.observableArray([task]);
};
var setting = new Setting();ViewModel
Les ViewModel contiennent :
- le modèle, également écouté par KnockOutJS via ko.observable.
- des données calculées via la méthode ko.computed, qui vont permettre d’étendre le modèle de base.
- la logique de la Vue.
Chaque ViewModel s’occupe d’une partie logique côté IHM.
// ViewModel associé au formulaire d’édition d’une tâche
var FormViewModel = function () {
// charge le modèle dans le ViewModel
this.setting = ko.observable(setting);
// ajoute une nouvelle tâche dans la liste
// et change la tâche courante avec celle-ci
this.addNewTask = function() {
var currentTask = new Task("new task");
this.setting().tasks.push(currentTask);
this.setting().currentTask(currentTask);
}.bind(this);
// retourne le nombre de tâches
// propriété calculé, étendant le modèle
this.remainingCount = ko.computed(function () {
return this.setting().tasks().length;
}.bind(this));
};
// crée le ViewModel et l’applique à la bonne vue
var formViewModel = new FormViewModel();
ko.applyBindings(formViewModel, document.getElementById("form"));
// ViewModel associé à la vue de la liste des tâches
var ListViewModel = function () {
// charge le même modèle
this.setting = ko.observable(setting);
// change la tâche courante
this.editTask = function(item) {
this.setting().currentTask(item);
}.bind(this);
}
// crée le ViewModel et l’applique à la bonne vue
var listViewModel = new ListViewModel();
ko.applyBindings(listViewModel, document.getElementById("list"));View
La Vue, décrite en html, récupère les données et les méthodes depuis le ViewModel. A l’aide de la propriété data-bind, nous déclarons toutes nos liaisons à des données et des méthodes.
// formulaire d’édition d’une tâche
<div id="form">
// méthode addNewTask définit dans le ViewModel
<button class="add" data-bind="click: $root.addNewTask"></button>
//bind la tâche courante depuis le ViewModel
<input id="new-todo" data-bind="value: setting.currentTask.title , valueUpdate: 'afterkeydown' " autofocus>
//bind le nombre de tâches ajoutées
<strong data-bind="text: remainingCount">0</strong>
</div>
//liste des tâches
<div id="list">
<ul id="todo-list" data-bind="foreach: tasks">
<li>
<label data-bind="text: title, event: { click: $root.editTask }"></label>
</li>
</ul>
</div>Le tag « input » affiche et modifie la valeur currentTask.title.
L’objet currentTask est aussi affiché dans la liste, via la propriété tasks du Modèle Setting.
Ainsi lorsque l’utilisateur clique sur un tag « label », le titre de la tâche s’affiche dans l’input du formulaire. Si ce dernier modifie cette valeur, le label de la liste est automatiquement mis à jour.
AngularJS
AngularJS n’est plus vraiment à présenter. La framework JS made in Google n’implémente pas à proprement parlé le pattern MVVM. On utilise le $scope comme ViewModel. On parle alors plus de MVW, pour Model-View-Whatever. L’important ici est de séparer la Vue et le Modèle.
Model
Nous n’avons pas besoin de créer de structure de Model spécifique. Angular se rappelle des valeurs précédemment stockées et envoie un évènement si elles sont différentes. Il nous suffit alors d’instancier un objet avec les propriétés que nous voulons utiliser. On peut également utiliser les Services d’AngularJS pour initialiser nos modèles depuis un serveur et les fournir ensuite au ViewModel.
//initialisation de la première tâche
var task = {title : 'new task'};
//créer un objet global contenant
//un tableau de tâches
//et la tâche courante
var setting = {};
setting.currentTask = task;
setting.tasks = [task];ViewModel
Côté ViewModel, nous nous rapprochons de ce que peut produire KnockOutJS. C’est pourquoi on compare souvent ces deux frameworks pour créer des applications MVVM. Nous déclarons deux ViewModel, qui garde une référence sur le même objet setting, qui est ajouté un $scope.
angular.module('myApp', [])
//ViewModel utilisé par le formulaire
.controller('FormViewModel', ['$scope', function($scope) {
//charge le modèle dans le ViewModel
$scope.setting = setting;
//méthode d’ajout d’une tâche
$scope.addTask = function() {
var newtask = {title : "new task"}
$scope.setting.tasks.push(newtask);
$scope.setting.currentTask = newtask;
};
//retourne le nombre de tâches
//la propriété calculée, permet d’étendre le modèle
$scope.nbtasks = function() {
var count = 0;
angular.forEach($scope.setting.tasks, function(todo) {
count += 1;
});
return count;
};
}])
//ViewModel utilisé par la liste
.controller('ListViewModel', ['$scope', function($scope) {
//charge le même modèle
$scope.setting = setting;
//méthode permettant d’éditer une tâche
$scope.editTask = function(task) {
$scope.setting.currentTask = task;
};
}]);View
Les Vues, décrites en HTML, déclarent leur ViewModel et indiquent quelles données et méthodes vont être liées. Encore une fois seule la syntaxe diffère de KnockoutJS. On utilise la propriété ng-model ou des doubles accolades pour lier le modèle à la vue.
//formulaire d’édition d’une tâche
<div ng-controller="FormViewModel">
<span>nb tasks : {{nbtasks()}}</span>
<form ng-submit="addTask()">
<input class="btn-primary" type="submit" value="add new task"/>
</form>
<input type="text" ng-model="setting.currentTask.title" size="30"/>
</div>
//liste des tâches
<div ng-controller="ListViewModel">
<ul>
<li ng-repeat="task in setting.tasks">
<span ng-click="editTask(task)">{{task.title}}</span>
</li>
</ul>
</div>ExtJS 5
ExtJS dans sa version 5 propose une implémentation revisitée du MVVM . En plus du ViewModel, il introduit une quatrième entité : le ViewController. Associé à une unique Vue, le ViewController va permettre de gérer le comportement et la logique de la Vue, alors que le ViewModel se cantonne au rôle de Presenter.
2.3.1 Model
Nous déclarons une tâche et un setting, avec la syntaxe ExtJS. Nous créons aussi une collection de tâches et une collection de settings. Cette dernière va nous permettre de récupérer les settings n’importe où. De plus nous utilisons cette collection pour ajouter des méthodes de manipulation sur le Modèle.
//structure d’une tâche, composée uniquement d’un titre
Ext.define(‘Task’, {
extend: 'Ext.data.Model',
fields: [{
name: 'title',
type: 'string',
defaultValue : 'new task'
}]
});
//donnée globale de l’application
//contient la liste de toutes les tâches
//et la tâche courante
Ext.define(‘Settings', {
extend: 'Ext.data.Model',
fields: [{
name: 'currentTicket',
},{
name: 'tasks',
}]
});
//définit une collection de tâches
Ext.define(‘Tasks, {
extend: 'Ext.data.Store',
model : 'Task
storeId : tasks
});
//définit une collection de settings
//cette collection ne contiendra qu’un seul élément
Ext.define('SettingsStore', {
extend: 'Ext.data.Store',
storeId : 'settings',
model : 'Settings',
//méthode appelée au chargement de l’application
load : function() {
//ajoute un seul element Settings
var settings = Ext.create('Settings');
settings.set(tasks, Ext.create('Tasks'));
this.add(settings);
//ajoute une première tâche
this.addTask();
},
//ajoute une nouvelle tâche
addTask : function() {
var newTask = Ext.create('Task');
this.getAt(0).get('tasks').add(newTask);
this.setCurrentTask(newTask);
},
//met à jour la tâche courante
setCurrentTask : function(task) {
this.getAt(0).set('currentTask', task);
}
});ViewModel et View Controller
Le ViewModel n’est utilisé que pour présenter les données.
Le ViewController est utilisé pour charger les données dans le ViewModel et gérer la logique de la Vue. Chaque ViewController récupère le même modèle Settings et le fournit à son ViewModel.
Ainsi les deux vues manipuleront le même objet sans interagir ensemble.
//ViewModel du composant graphique FormTask
Ext.define('FormTaskViewModel', {
extend: 'Ext.app.ViewModel',
alias: 'viewmodel.formtask',
//data à binder
data : {
settings : null
},
//data “calculée” à binder
formulas : {
nbTasks : function(get) {
return get('settings.tasks').count();
}
}
});
//ViewController du composant graphique FormTask
Ext.define('FormTaskViewController', {
extend: 'Ext.app.ViewController',
alias: 'controller.formtask',
//méthode appelée automatiquement à l’initialisation
init : function() {
//récupère le model settings
var setting = Ext.getStore('settings').getAt(0);
//charge le modèle dans le ViewModel
this.getViewModel().set('settings', setting);
},
onClickCreateButton : function(cmp) {
//ajoute une nouvelle task
this.getViewModel().get('settings').store.addTask();
}
});
// ViewModel du composant graphique GridTicket
Ext.define('MVVM.view.GridTicketViewModel', {
extend: 'Ext.app.ViewModel',
alias: 'viewmodel.gridticket',
data : {
settings : null
}
});
//ViewController associé à la vue GridTicket
Ext.define('MVVM.view.GridTicketViewController', {
extend: 'Ext.app.ViewController',
alias: 'controller.gridticket',
init : function() {
//récupère le model settings
var setting = Ext.getStore('settings').getAt(0);
//charge le modèle dans le ViewModel
this.getViewModel().set('settings', setting);
},
onSelectRow : function(cmp, model) {
//modifie la tâche courante par celle sélectionné
this.getViewModel().get('settings').store.setCurrentTicket(model);
}
});View
Les Vues en ExtJS sont décrites dans des objets. Chaque Vue déclare son ViewModel et son ViewController, mais n’appelle jamais ses instances. Il suffit alors d’utiliser le mot clef ‘bind’ pour lier la valeur dans le ViewModel à celle de la Vue.
//Composant graphique définissant le formulaire d’édition d’une tâche
Ext.define('FormTask', {
extend: 'Ext.form.Panel',
//déclaration du viewcontroller associé
controller: 'formtask',
//declaration du viewmodel associé
viewModel: {
type: 'formtask'
},
items : [{
xtype : 'button',
label : 'Create new Task',
//fonction définit dans le ViewController
handler : 'onClickCreateButton'
},{
xtype : 'textfield',
fieldLabel : 'Title',
name: 'title',
allowBlank: false,
bind : {
//affiche le titre de la tâche courante
value : '{settings.currentTask.title}'
}
}, {
xtype : 'label',
//affiche le nombre de tâches
bind : '{nbTasks}'
}]
});
//Composant graphique définissant la liste des tâches
Ext.define('MVVM.view.GridTicket', {
extend: 'Ext.grid.Panel',
xtype : 'grid-ticket',
controller: 'gridticket',
viewModel: {
type: 'gridticket'
},
// bind la collection de tâches
// le composant Ext.grid.Panel s’occupe
// d’afficher automatiquement toutes les tâches
bind : {
store : '{settings.tickets}'
},
//affiche dans cette colonne la propriété ‘title’ de chaque tâche
columns : [{
text: 'Tasks',
dataIndex : 'title'
}],
//au clic sur une ligne, on exécute la méthode 'onSelectRow'
listeners : {
select : 'onSelectRow'
}
});Conclusion
Chaque framework a sa propre manière et syntaxe pour implémenter le pattern MVVM. Le principe d’indépendance entre la Vue et le Modèle est à chaque fois respecté et tous proposent des outils pour mettre en place un data-binding entre la Vue et le ViewModel.
Chaque framework a ses propres avantages :
- KnockoutJS est peu intrusif en étant une simple librairie.
- AngularJS est le plus simple syntaxiquement et le plus éprouvé par la communauté.
- ExtJS pousse encore plus à découper notre application et à structurer notre code.
Mais le pattern MVVM n’a pas que des avantages. Pour de petits projets, il peut être contre-productif de proposer une telle architecture. De plus pour de très gros projets avec de nombreux ViewModel, le data-binding peut consommer la mémoire de manière considérable.
Il n’est donc pas interdit d’implémenter son propre mécanisme de liaison, tant que l’on respecte le découpage complet entre la Vue et le Modèle.
Oculus Rift (Positional Tracker)
2015 est bien parti pour être l’année de la réalité virtuelle et augmentée. A l’image de Microsoft qui a dévoilé ses HoloLens la semaine dernière, de nombreux constructeurs travaillent sur le sujet.
Nous aussi, en tant que fournisseur de solutions digitales métier, nous regardons de très près ces dispositifs pour lesquels nous avons identifié plusieurs usages professionnels prometteurs.
L’objet de ce billet n’est pas de faire un retour sur nos activités de R&D concernant la réalité virtuelle et augmentée mais de décrire la résolution (une des résolutions) technique au problème de disponibilité de la caméra sur le casque Oculus Rift DK2, le périphérique de réalité virtuelle de Facebook.
Au vu du nombre de messages sur les forums traitant de ce problème, on peut en conclure qu’il est très fréquemment rencontré. De quoi s’agit-il exactement ? L’anomalie concerne la non reconnaissance de la webcam de l’Oculus Rift. Elle se matérialise dans l’outil de configuration par la mention « Waiting for camera » au lieu et place du numéro de série.
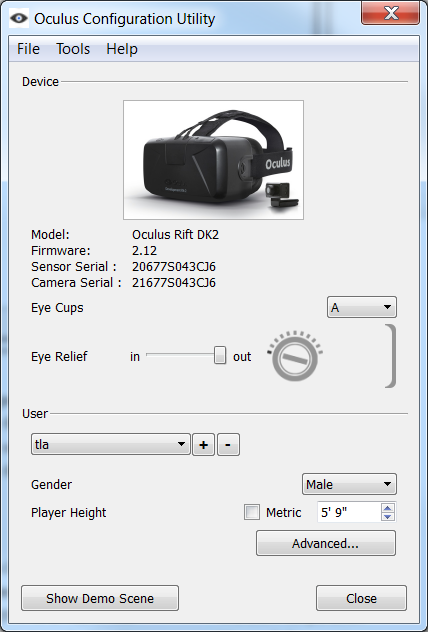
Le champ « Camera Serial » ne doit pas afficher « Waiting for camera », ici il n’y pas de problème.
La webcam n’a pas un usage classique dans le sens où elle ne filme pas mais sert à tracer la position de l’utilisateur. Pour revenir au fameux bug, il se produit lorsque pour diverses raisons, comme par exemple suite à une mise à jour de l’Oculus Runtime, le driver utilisé par la webcam n’est pas celui fourni spécialement par Oculus mais un driver générique de Microsoft.

Sous « Imaging devices » (« Périphérique d’acquisition d’images » en français), la webcam doit apparaître avec le libellé « Oculus Positional Tracker » et non « Camera DK2 »
La désinstallation et réinstallation du Runtime Oculus ne règle pas le problème, ce qu’il faut faire c’est supprimer les drivers pour les réinstaller dans la version correspondant au Runtime. Pour cela il faut se rendre dans l’utilitaire Windows et désinstaller expressément « Oculus Positional Tracker Driver ».
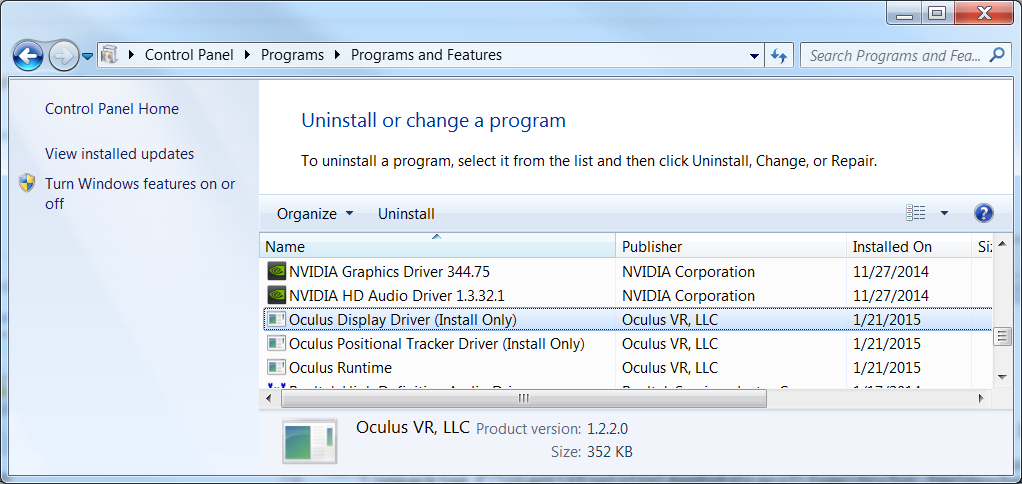
Il faut supprimer les anciens drivers, avant de les réinstaller.
Là aussi, cela peut coincer. Nous avons constaté que si les drivers étaient bien supprimés du système ils continuaient à figurer dans le « Panneau de configuration » ce qui a le fâcheux inconvénient d’empêcher leur réinstallation. Il faut donc éditer la base de registre avec regedit et supprimer les enregistrement contenant « Positional Tracker Driver ». Une fois ceci fait, on peut procéder à l’installation.
Pour cela, il faut éditer le ficher « ovr_install.txt » se trouvant dans le répertoire d’installation du Runtime, par exemple :
C:\Program Files (x86)\Oculus\Logs/ovr_install.
Dans ce fichier la ligne suivante, indique l’emplacement du fichier MSI des drivers :
Unpacking C:\Users\Stagiaire\AppData\
Il suffit alors de l’installer (sur un système 32bit, il faut exécuter OculusMSI_x86.msi).
Et voilà, un petit tour dans l’utilitaire de configuration Oculus devrait confirmer que la caméra est dorénavant correctement reconnue.
Développer efficacement avec Phonegap
Une multitude d’outils
En matière d’outils de debug et de développement, le choix ne manque pas. Que vous utilisiez Linux, Windows ou MacOsX vous êtes libre de choisir les outils.
Adobe, bien qu’étant spécialiste des IDE et solutions complètes de développement, ne nous fournit pas encore un outil digne du nom d’IDE. A part la ligne de commande et une petite interface permettant d’appeler ces commandes (voir l’article), nous sommes loin des solutions auxquelles a pu nous habituer Adobe.
C’est donc à nous développeurs, de trouver le moyen le plus efficace de créer des projets, de les éditer, de les tester et de les livrer. Plusieurs solutions, libres dans la plupart des cas, vont nous aider à pallier à ce manque.
Le navigateur, un des outils les plus efficaces
Que ce soit Firefox, Chrome, Safari, ou encore IE (et oui c’est encore utilisé ;-)), le navigateur reste l’outil le plus pratique pour debugguer votre application. Bien sûr vous ne pourrez pas tester les appels aux plugins, mais c’est un must pour de la mise en page, animations, et l’inspection des variables.
Oui mais alors, comment déclencher l’évènement deviceready ?
Plusieurs solutions sont possibles et sont décrites sur stackoverflow. Le plus simple est d’utiliser le code suivant :
if (navigator.userAgent.match(/(iPhone|iPod|iPad|Android|BlackBerry)/)) {
document.addEventListener(“deviceready”, onDeviceReady, false);
} else {
onDeviceReady();
}L’idée est de détecter que l’on se trouve sur un appareil mobile pour s’abonner à cet évènement. Dans les autres cas, cela signifie que nous sommes sur un navigateur et que nous ne sommes pas en mesure d’avoir cet évènement, nous devons donc appeler la fonction onDeviceReady.
Ripple emulator
Ripple emulator est un plugin fonctionnant avec Firefox et/ou Chrome, il permet de visualiser le rendu de votre application dans votre navigateur.
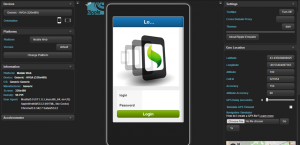
Ripple emulator permet d’émuler certains composants d’un appareil mobile, tels que l’orientation du matériel, la géolocalisation, la détection de mouvement, parfait pour simuler un cas d’utilisation réel.
C’est une solution très efficace, pour autant qu’on utilise les versions de Phonegap compatibles avec Ripple.
Phonegap developer app
Cette application qui embarque tous les plugins de base, permet d’utiliser toutes les fonctionnalités de l’appareil. Cette application va de paire avec une instance de serveur Phonegap qu’on lance depuis sa machine.
La première chose à faire est de télécharger l’application Phonegap app developer
$ phonegap serve
[phonegap] starting app server…
[phonegap] listening on 192.168.1.12:3000
[phonegap]
[phonegap] ctrl-c to stop the server
[phonegap]Une fois connecté, l’application est automatiquement rechargée lors de l’édition des sources. C’est un bon début pour être efficace mais il manque :
- cruellement la possibilité d’utiliser le remote debugging,
- aussi la possibilité d’utiliser des plugins tiers.
Pour résumer, c’est un moyen assez efficace pour tester son application, mais pas pour la debugguer.
Chrome Web Tools
Le remote debugging avec Chrome est l’un des meilleurs outils à mon sens, si ce n’est le meilleur. Pour l’activer, il faut avoir activer le mode développeur sur l’appareil, avoir déployé votre application, et connecter votre appareil en usb.
Pour accéder à la console javascript de votre application , il faut ouvrir Chrome, et accéder à chrome://inspect
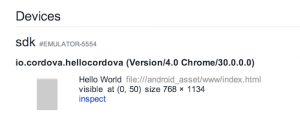
Attention : pensez à cocher la case ‘Discover usb devices’.
En cliquant sur le lien ‘inspect’, une console javascript s’ouvre et permet d’inspecter directement l’application, idéal pour mettre des points d’arrêts et monitorer les performances.
Nodejs et live reload
La solution qui me plait le plus en terme de productivité reste le live reload de l’application lors de modification des sources.
L’idée est de ne pas embarquer les sources html/javascript dans l’application Phonegap mais de les servir depuis un serveur Nodejs avec Grunt ou Gulp (voir l’article)
Un seul fichier est embarqué dans l’application (index.html), et redirige vers notre serveur Nodejs.
<html>
<head>
<meta http-equiv=”refresh” content=”1; URL=http://192.168.1.12:3000”>
</head>
<body>
Redirecting …
</body>
</html>Seul l’ajout ou modification de plugins nécessite un redéploiement de l’application sur l’appareil.
On bénéficie alors du remote debugging et du live reload, mais surtout on teste sur du vrai matériel.
Conclusion
Pour résumer, Phonegap laisse le développeur dans l’embarras du choix concernant l’outillage et le processus de développement. La communauté Phonegap / Cordova est active ces derniers temps et laisse présager de beaux jours (belles nuits) de développement pour l’année à venir !
Dans un prochain article, nous aborderons le framework ngCordova qui marie Cordova et AngularJS.
Interviews DocDoku & Aerospace Valley
François Dorgeret, en charge des projets innovants au sein du pôle Aerospace Valley, et moi-même avons participé à une interview dans le cadre du salon SIANE 2014.
L’occasion pour nous de présenter notre vision de l’usine du future et la manière dont elle est abordée au sein de son DAS chez Aerospace Valley.
DocDoku recrute un(e) Business developer confirmé(e) sur Toulouse
Entreprise
La mission de DocDoku est d’aider les organisations à digitaliser leur métier.
Société technologique spécialisée dans la digitalisation des applications d’entreprise. nous développons la plate-forme collaborative et innovante open source DocDokuPLM qui aide les organisations à accroître leur efficacité et leur compétitivité.
La société se compose d’une équipe d’ingénieurs et consultants passionnés de technologies dont l’expertise est aujourd’hui reconnue dans les domaines du mobile, du cloud et du web moderne pour le SI.
Poste
Dans le cadre de sa forte croissance depuis sa création, DocDoku se renforce et offre un poste d’ingénieur commercial / business developer confirmé pour son agence de Toulouse.
Avec une réelle approche de conseil et en participant à la définition de la stratégie commerciale, vous constituerez et développerez un portefeuille de clients (ETI).
Ainsi vous serez l’interlocuteur commercial de nos clients pour la vente de nos services et produits innovants au national voire international.
Responsabilités
Gérer le processus complet de vente, de l’identification du prospect à la signature du contrat à savoir :
- identification et prospection clients (prise de RDV, salons, relations publiques…),
- avant vente et démonstrations de nos solutions innovantes,
- propositions commerciales, en lien avec nos équipes techniques,
- développement du portefeuille clients et entretien de la relation client,
- optimisation des campagnes et de nos ventes avec l’equipe marketing,
- maintien en continu de notre CRM à jour (actions, contacts, opportunités…),
- évaluation et optimisation de la satisfaction client.
Profil
De formation supérieure (BAC+4/5), issu(e) d’une école d’ingénieurs, école de commerce ou équivalent, vous disposez d’au moins 5 ans d’expérience technico-commerciale réussie au cours de vos anciennes expériences dans le domaine des TIC.
Vous connaissez bien le marché des TIC et leurs usages, ses acteurs ainsi que l’environnement technologique associé.
Vous avez de l’énergie, un sens aigu du relationnel et un dynamisme à toute épreuve.
Animé(e) par le goût d’entreprendre, vous êtes prêt(e) à relever de nouveaux challenges et êtes doté(e) d’une forte sensibilité technologique.
Vous êtes ambitieux et vous rejoindrez notre équipe à un moment clé de notre développement vous ouvrant à terme de réelles opportunités de carrière.
Alors écrivez nous ici.
Lieu
Toulouse
Salon SIANE – Retour sur la 3ème nuit de l’ingénierie « Usine du Futur »
A l’occasion du salon SIANE, le 22 octobre se tenait la 3ème nuit de l’ingénierie.
Une centaine de personnes était présente pour échanger autour du thème de l’Usine du Futur.
Invité par la Société Nationale des Ingénieurs de France, nous avons eu l’occasion de présenter les apports technologiques potentiels de DocDoku aux usines du futur pour qu’elles soient numériques, connectées, intelligentes tout en restant humaines.
Michel Roboam, directeur de l’ingénierie de production chez Airbus, nous a décrit la vision de l’avionneur quant à l’usine de 2020. La voici en images :
La confirmation que l’Usine du Future sera sans aucun doute une usine numérique et digitale, connectée au système d’information de l’entreprise étendue, afin d’apporter toute l’intelligence nécessaire à l’homme pour améliorer sa productivité, garantir la qualité de production et ainsi la compétitivité de son entreprise. En résumé, une usine qui sera capable de diffuser les bonnes informations (produit et processus) au bon moment et aux bonnes personnes dans la chaîne de valeur.