Introduction
Le but de cet article est de présenter brièvement le concept de DevOps, illustré par une implémentation concrète dans un environnement applicatif de microservices Restfull, développés dans le contexte d’une approche agile.
La première partie est consacrée au rappel des principes de DevOps et à la présentation du schéma architectural d’une chaîne DevOps avec Github, Jenkins, Artifactory et Ansible.
La deuxième partie présente une autre chaîne DevOps avec Github, Jenkins, Artifactory et OpenShift.
1 Agile et DevOps main dans la main
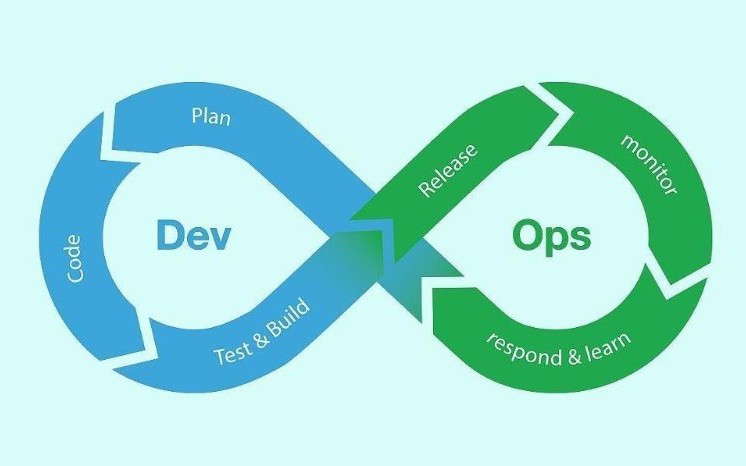
Le développement d’applications dans le cadre d’une approche agile impose des livraisons fréquentes au rythme des itérations, tout en préservant la qualité des livrables, la maîtrise des releases et l’adaptabilité à différents environnements techniques et applicatifs. Pour répondre à ces exigences, l’automatisation des processus est nécessaire ainsi qu’une synergie entre les équipes de développement et celles des opérations. C’est là que DevOps apporte la solution à ces problématiques d’intégration continue (IC) et de déploiement continu (DC).
2 Les apports de DevOps
- Fréquence des déploiements accrue
- Délai d’exécution réduit pour les modifications
- Récupération plus rapide en cas de problème
- Une sécurité plus robuste et mieux intégrée
- Qualité accrue
- Feedback rapide
3 Les outils de DevOps
A chacune des étapes du workflow automatisé de DevOps correspondent des outils open source ou propriétaires (ci-dessous une liste non exhaustive) :
- Versionning-commit de code : SVN, Git, TFS, GitHub, Tuleap
- Qualité de code : SonarQube, IntelliJ, Eclipse
- Sécurité : SonarQube, Checkmarx, dependency-check-maven
- Tests : JUnit, Mockito, Selenium, Postman, Gatling, Jmeter
- Build : Maven, NPM
- Intégration/Déploiement/Livraison continus : Jenkins, Teamcity, Bamboo, TFS
- Gestion des releases : Nexus, Artifactory
- Déploiement : Ansible, Docker, OpenShift, Azure, AWS, VmWare
- Performance, monitoring : Nagios, Zabbix, Spring boot Actuator
- Logs : Splunk, Logstash, Elasticsearch
4 Exemple d’une mise en oeuvre avec Ansible
La chaîne DevOps décrite ci-dessous permet d’assurer des déploiements sur différents environnements techniques : INT, VAL et PROD.
Elle est composée des éléments suivants :
- GitHub
- Git local installé sur chaque poste développeur
- Jenkins assure les builds (compilation/packaging)
- Artifactory : repository des artifacts
- Ansible assure les déploiements
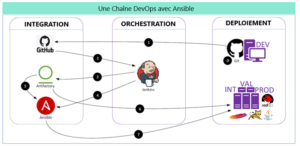

Dans ce cas d’utilisation, un job Jenkins pilote le build (compilation, tests unitaires automatisés, audit de code par SonarQube, packaging). L’artifact résultant (un jar, dans le cas d’un microservice springboot) est uploadé dans Artifactory.
En post-action, le job va déclencher un script Ansible chargé de déployer le microservice dans les différents nœuds d’un cluster.
4.1 Concepts utilisés dans Ansible
Ansible permet d’automatiser les tâches de configuration et de déploiement des applications. Son administration se fait par le biais d’une interface Web, Ansible Tower.
Cette administration est centralisée dans une seule machine, le Control Node, où est installé Ansible. Aucune installation d’un agent n’est faite sur les autres machines gérées par Ansible (Managed nodes). Les concepts énumérés ci-dessous permettent de comprendre le fonctionnement de Ansible :
- Inventory (inventaire) : liste des nœuds gérés, spécifiant des informations telles que les adresses IP. Cette liste peut être organisée selon différents critères : localisation, fonction, …
- Module: c’est une unité de code Ansible spécialisée sur un type de fonctionnalités qu’on peut invoquer pour exécuter des tâches : administration des utilisateurs sur un type spécifique de base de données, gestion des interfaces VLAN sur un type spécifique de périphérique réseau, etc …
- Task: c’est une unité d’action Ansible qu’on peut exécuter par une commande
- Playbook: Liste ordonnée de tâches, enregistrées à exécuter à plusieurs reprises. Les playbooks peuvent inclure des variables ainsi que des tâches. C’est des fichiers écrits en YAML.
- Roles : les rôles sont définis pour charger automatiquement des fichiers de configuration, tâches et gestionnaires. Ils sont organisés sous forme de fichiers dans des répertoires ayant un nommage et une structure pré-définis. Les rôles sont invoqués dans les playbooks (comme les imports dans un fichier java).
Exemple de mise en œuvre d’Ansible dans Integrating Ansible with Jenkins in a CI/CD process.
En résumé
Dans cette première partie, ont été rappelés les concepts de DevOps en relation avec une approche agile du développement d’applications. Un premier schéma architectural de chaîne DevOps est présenté ayant comme outil de versionning et de repositories GitHub et Artifactory, Jenkins comme pilote de l’intégration et du déploiement continus.
Cette chaîne utilise Ansible pour exécuter les déploiements sur les différents nœuds et environnements de l’application. Ansible est installé sur un nœud unique et permet via les playbooks et son interface Ansible Tower d’automatiser le processus de déploiement sur un grand nombre de nœuds (serveurs, périphériques, …).
Dans la deuxième partie, un autre schéma architectural d’une chaîne DevOps utilisant OpenShift sera présenté.